

Bletchley 公园的阿兰•图灵塑像 (Jon Callas/Flickr)
图灵是20世纪最伟大的数学家之一。作为现代计算机概念的缔造者,他的密码破译工作在第二次世界大战中起到了决定性的作用。在那个创意无限的计算机黎明时代,图灵率先提出的测试,说来似乎很简单:如果一台计算机通过对话,能使人们认定它是人类,那么这台计算机便被认为是具有智能的。
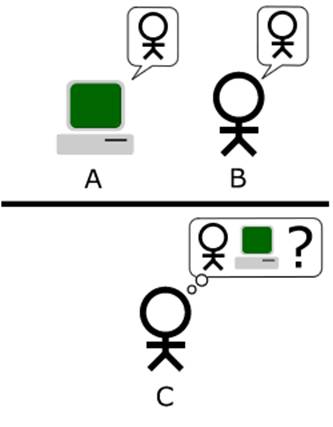
图灵试验的标准模式:C使用问题来判断A或B是人类还是机械。对象为:一个具有正常思维的人(代号B)、一个是机器(代号A)。如果经过若干询问以后,C不能得出实质的区别来分辨A与B的不同,则此机器A通过图灵试验。
在现代社会,无论是GPS导航系统与Google搜索引擎,还是自动柜员机与苹果Siri,更遑论象棋大师深蓝(Deep Blue)和满腹经纶的沃森(Watson),人工智能无处不在。但是,迄今为止,没有一台计算机通过了图灵测试。虽然如此,在尝试通过图灵测试的漫漫征程上,模拟人类思维的愿望不断激励着我们。这一原动力,对计算机科学乃至认知科学的发展,产生了深远影响。
而现在,我们有理由相信,一台内核代码已经写就的计算机,拥有通过图灵测试的能力。
“两项革命性的信息技术进步,可能将重新给被闲置已久的图灵测试,带来新的任务,”法国国家科学研究中心的认知科学家罗伯特•弗兰茨(Robert French)在4月12日的《科学》杂志上撰文称,“第一步是准备数量巨大的原始数据:输入的内容包括视频资料和完备的声音环境信息,以及随意的谈话内容和关于各种各样事物的技术文档。第二步是能够整理、收集、处理这些丰富数据的复杂技术。”
这有没有可能创造出相当于人类大脑的认知水平的神经连结网络?它能感知到我们所感知的吗?
图灵第一次进行他的测试,是在一次聚会时。他巧妙的实验令人印象深刻:参加者努力让评判者相信他们的性别是伪装的(图灵本人由于他的同性恋取向受到了严酷的迫害)。那时候,这种创建等效于人类大脑认知方式的低水平神经网络的想法还不存在。然而,复制人类的思想似乎很有可能,相比之下似乎更简单。
我们一般认为,人类的思维是逻辑性的,而计算机能够运行逻辑性的命令。因此,我们的大脑应该是可计算的。计算机科学家由此认为,二十年之内,或许不超过十年,我们就可以看到这样激动人心的事情:人们无法根据对话分辨出,对方是计算机还是人类。
这个过分简约的构想,被证明是建立在错误的理论基础上的。认知过程要远比20世纪中叶的计算机科学家及心理学家所设想的复杂得多。并且令人沮丧的是,在运用逻辑学描述我们的思想过程时,科学家遇到了非常大的困难。并且我们越来越清楚:根据人类大脑所特有的,适应快速变化的外界环境、整合信息碎片等一系列特殊功能来看,模仿人类思维几乎是无法完成的任务。
“对于现实中众多不确定性而言,符号逻辑本身过于脆弱,”斯坦福大学研究机器智能模拟的计算机科学家诺亚•古德曼(Noah Goodman)如是说。尽管如此,现在被我们认为已经失败的传统AI,技术上依旧颇具启发性。因为它们彻底改变了,我们对于人类大脑运作方式的看法。挫折过后,不断涌出的是许许多多极其重要的认知科学新观点。
直到20世纪80年代中期,图灵测试一直都是被放弃闲置的探索领域(尽管今天,它衍生出了专为虚拟聊天机器人设置的年度Loebner奖,同时即时虚拟广告机器人在我们的日常生活中也益发普遍)
(康奈尔大学创新机器实验室的两部虚拟谈话机器人正在进行非常有趣的唠嗑)
与此同时衍生出的是现代认知科学和人工智能的两个主要研究方向:
1.推算事件发生的概率,做出准确判断。(称为概率性)
2.在与简单、微小的程序的互动过程中,得出复杂的行为模式。(称为连结性)
和那些像深蓝(Deep Blue)(曾因击败国际象棋大师Garry Kasparov扬名)一样使用“蛮力”的电脑程序的计算特点不同,人们认为这些程序至少精确反映出了,人类思维中产生的某些特有现象。
迄今为止,所谓“概率性”和“连结性”这两大人工智能研究新思路,指导开发出了一系列现实生活中被广泛使用的人工智能产品:自动驾驶汽车,Google搜索引擎,自动机器翻译,以及IBM开发的能巧妙回答任何刁钻古怪问题的Watson电脑。

IBM的Watson电脑击败Ken Jennings,他是Jeopardy! 节目的人类最高水平玩家。
但是美中不足的是,它们在某些方面能力仍旧有限——“如果你说:‘Watson,给我做晚饭好不好,’或者‘Watson,写首十四行诗吧,’他会憋炸的。”古德曼这样说道。但是人们不断上涨的使用(或调戏,好吧)欲望使它们的性能得以飞快进步,数据库更详实。
“你所说过的、听到的、写下的、或者是读到的每一个字,每一句话,以及每一个看到的场景,每一段经历的声音片段,一并同其他成百上千、甚至成千上万的人们的相关数据,都被录制下来并可随时调用。久而久之,甚至触觉以及嗅觉传感器也可以被接入以全面丰富我们这个充满图像和声音的数据库。”作为对MIT(麻省理工)研究员戴伯•罗伊(Deb Roy)的相关研究的延伸,弗兰茨在《科学》杂志上这样设想。戴伯曾经录制了9万小时的视频,内容是关于他襁褓中的儿子清醒状态下的认知发展过程。
假定我们拥有可以编目、分析、串联和交叉全部海量信息的处理软件,以及备有上述数据库和分析系统的程序,应该完全能够使得一台计算机回答现今的AI们无法回答的棘手问题。这最终意味着通过图灵测试。
密歇根大学的人工智能专家赛汀德•辛(Satinder Singh)对数据所显示的前景充满了信心:“大容量数据库终会造就一台极具灵活性的人工智能机器。”
但这样来说,梳理所有曾经学习过的问题数据就显得重要了许多。计算机要懂得:什么更值得记住,什么更值得去预测。可是,如果你把一个孩子领进屋内,让他自由自在、随心所愿,不交给他任何任务,他为什么会自发地做他想做的事情呢?所有的这类问题都变得异常有趣。
“为了变得更渊博,更灵活,更有能力,一个人必须要被动力和好奇心所驱使,从而提炼出重要的事情,”辛说:“这些对计算机来说,都是巨大的挑战。”
“一架机器要通过图灵测试,一定要充满着人类的情感与欲望吗?。就像是弗兰肯斯坦(玛莉•雪莱(Marry Shelley)笔下的人造人),或者有生命的泥人(Golem希伯莱传说中用粘土、石头或青铜制成的无生命的巨人,注入魔力后可行动)一样吗?”墨西哥国立自治大学的计算机科学家卡洛斯•格申森(Carlos Gershenson)充满了疑问。但是这和更基本的问题一样,难以回答。
“这做起来一定很困难,可是我们这样做的目的是什么?”他充满了疑问。