
查看大图,点 这里
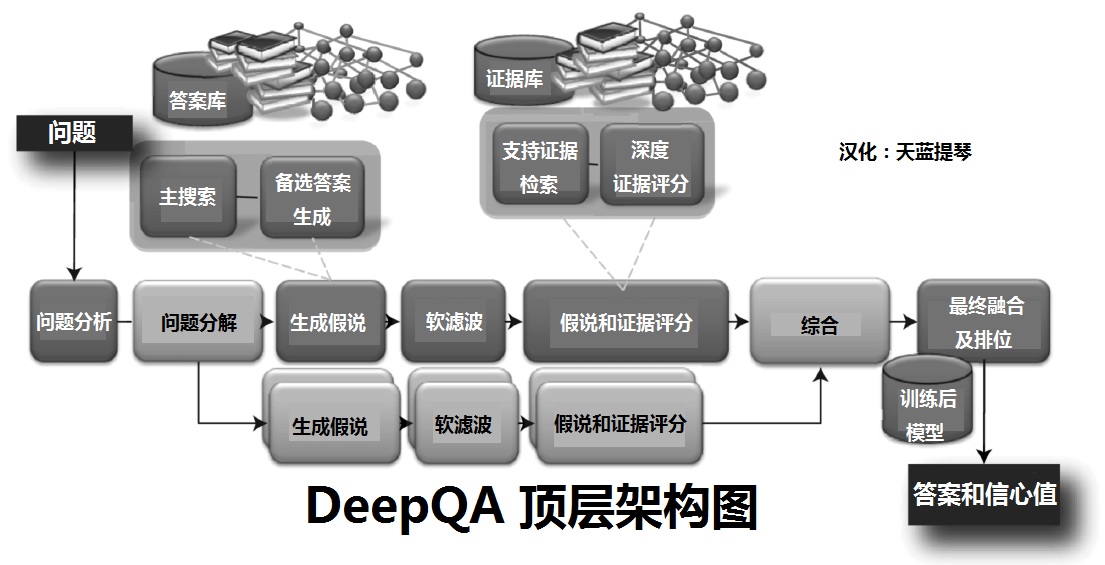
Watson在 智力问答游戏“Jeopardy!”中让人类最聪明的个体尝到了失败的滋味:曾经在这个节目中创下74连胜的Ken Jennings甚至在回答终极 Jeopardy! 问题时,在题板上写下“I FOR ONE WELCOME OUR NEW COMPUTER OVERLORDS (我个人欢迎我们的新电脑霸主)”并认输。作为在Watson体内运转的软件,DeepQA问答系统是Watson实现这一壮举的核心。如果把 Waston看做是参加 Jeopardy! 的人类选手,那么DeepQA就是这位选手回答问题的思路和方法。
准备工作:建立知识库
想要用DeepQA系统来回答 Jeopardy! 里包罗万象的问题,怎么也得学富五车吧(用五辆卡车才装得下的硬盘阵列...)。也就是说DeepQA要预先搜集各个领域的材料。研究小组会分析一些模拟问题,并基于这些问题来人工指定Watson的知识库需要覆盖的基本范围,形成一个包含了各种百科全书、词典、新闻、文学作品等内容的知识库基本包。然后DeepQA会运用以下方法自动生成一个知识库扩展包,分为四个步骤:
- 依据基本包中的某个“种子文档”,从网上取得可能相关的文档资料;
- 摘录相关文档资料中出现的知识点;
- 根据这些知识点所覆盖到的新信息量来给知识点打分;
- 将新信息最翔实的知识点加入知识库扩展包中。
在比赛中,Watson将断开网络,只能使用保存在硬盘中的知识库基本包+扩展包作为自己的知识储备,这和人类参赛选手是一样的。
问题分析
在这一环节,DeepQA尝试去理解问题,搞清楚问题到底在问什么;同时做一些初步的分析来决定选择哪种方法来应对这个问题。
问题分类
面对一个问题时,DeepQA先提取问题中需要特殊处理的部分;包括一词多义、从句的句法、语义、修辞等可能为后续步骤提供信息的内容。
然后DeepQA会判断问题的类型。问题可能属于谜题、数学题、定义题等不同类型,而每种类型都需要各自的应对方法。
这一步还会识别出双关语、限制性成分、定义性成分,甚至有时能识别出解决问题所需的整个子线索。
焦点检测和LAT
有些题目中的关键字能让DeepQA在没有尝试语义分析时就判断出答案的类型。这类关键字称为LAT(Lexical answer type,定型词)。判断某一个备选答案是否对应一个LAT是重要的评分方法,也是一个常见的误差来源。
DeepQA系统的一大优势就是可以利用各种相互独立的答案分类算法,每种但其中大部分算法都依赖于自己的分类系统。DeepQA研究小组发现,最好的方法不是将他们整合到同一个分类系统中,而是将LAT映射到他们各自的分类系统中。
如果用备选答案去替换一个问题中的焦点,那么这个问题就会变为一个事实称述句。比如说,“When hit by electrons, a phosphor gives off electromagnetic energy in this form(当荧光粉被电子击中时,发出这种形式的电磁能量)” 的焦点是 “this form(这种形式)”。
焦点通常包括了一些和答案相关的信息。(但并不总是如此。)焦点通常是线索里某种关系中的主语或者宾语,用某个备选答案替换它是一种获得证据的有效方法。
关系检测
绝大多数题目里的要素之间是有相互关系的,可能是主谓宾的结构关系,也可能是语义上的关系。比如这个问题“They're the two states you could be reentering if you're crossing Florida's northern border (如果你穿过佛罗里达州的北部边界,那么你会进入这两个州)”中存在着地理位置上的相关关系:
佛罗里达州->北部->答案的两个州
从焦点和LAT探测,到段落和答案评分,Watson都在使用关系检测。不过,由于 Jeopardy! 涉猎的问题范围之广,问题表述变化之多,使得Watson在运用关系检测后能直接从数据库中产生答案的比例只占了所有问题的2%。
问题分解
DeepQA用基于规则的深度语法分析和统计分类方法来确定一个问题是否应该被分解,以及怎样分解才最容易回答。
这种分解的基本假设是:在考虑了所有证据和相关算法之后,最优分解法所得答案将会在评分环节蟾宫折桂。虽然有些问题并不需要分解就能形成答案,这种方法仍然会提高DeepQA对于所有答案的信心。
对于可以并行分解的问题,DeepQA会对分解后的每一个分支做一套完整的备选答案生成流程,然后用一个可定制的答案合成模块来综合出最终备选答案。这个过程用浅灰色表示在DeepQA顶层架构图中(最下方的部分)。
DeepQA也支持那些分解后的子线索呈网状交织的问题。对于这类问题,DeepQA会对线索网中的每一条线索进行一次完整的备选答案生成流程,然后用专用的算法合成最终答案。为某些特定问题开发的专用的合成算法可以作为插件轻松地加入到整个“可定制的答案合成模块”的公共框架中。
生成假说
使用问题分析的结果,DeepQA可以从知识库中寻找那些长度接近答案所需长度的知识片段,产生备选答案。当每个备选答案填入题目中的空缺处后就成为了一种假说,而DeepQA则需要怀有不同程度的信心来证明这种假说的正确性。
对于在“生成假说”中进行的搜索,称之为“主搜索”,以区别后面将会提到的在“证据搜集”中的搜索。
主搜索
主搜索的目标是倚赖问题分析的结果,揪出尽可能多的、潜在包含了答案的内容。期望能通过深入的内容分析来得到备选答案,并在各种或支持或反对的证据帮助下提高备选答案的精确性。因此,DeepQA研究小组设计了一个平衡了速度、记忆和精度的系统。通过不断调整这个系统,研究小组能够得出那个在准确性和可计算资源之间取得最佳平衡的搜索结果数量和备选答案的数量。最终结果稳定在:对于85%的问题,DeepQA都能在前250个备选答案中找到正确答案作为最终备选答案。
运用了各式各样的搜索技术,包括不同构造方法的多文本搜索引擎(比如Indri和Lucene),文件搜索,段落搜索,用SparQL的三元组存储(http://en.wikipedia.org/wiki/Triplestore)进行基于知识的搜索,单个问题产生多个搜索请求,回填信息列表以满足问题中提到的关键限制。
其中,三元组存储是一种为了存储和取回资源描述架构(RDF,Resource Description Framework)的元数据而专门建立的数据库。 一个主-谓-宾结构的短句称为一个三元组(triples),比如“Matrix67是文科生”或者“果壳众解救丁老湿”。而SparQL则是为RDF开发的一种查询语言和数据获取协议。
文本中的人名、地名、组织名、时间、数量、货币价值、百分比等等内容称为已命名实体(named entity,http://en.wikipedia.org/wiki/Named_entity_recognition)。比如“天蓝提琴在2007年买了300股中石油的股票”这句话在经过已命名实体识别之后,就会被注释成如下形式:
天蓝提琴人名>在2007年时间>买了300股数量>中石油机构名>的股票。
主搜索中的三元组查询是基于线索中的已命名实体的。例如在数据库中寻找线索里提到的已命名实体的所有相关实体,或者在检测到语义关系时使用更加精确的查询。对于少量称为“闭合LAT(closed LAT)”的LAT,备选答案可以从一个LAT实例库的固定列表中取得,比如“美国总统”或者“国家”这样的词。
备选答案生成
这一步会处理主搜索的结果。对于拥有一个精确标题的资料,标题本身将作为备选答案。DeepQA还会通过子字符串分析和链接分析(如果有链接的话)来生成一些基于这个标题的变种备选答案。段落搜索的结果需要更加细化的段落文本分析才能得到备选答案:比如已命名实体检测法。对于三元组存储或者反向字典搜索,搜索结果将会直接作为备选答案。
如果在这一阶段生成的备选答案里没能包括正确答案,那么Watson就只能将这题拱手让人了。所以DeepQA会在这一步重视数量,降低精度要求,使得备选答案的数量可能会变得非常庞大;同时祈祷后续步骤能够从这备选答案的汪洋大海中打捞出确答案。所以问答系统设计的目标之一就是在处理流程的初期忍受大量无关信息,并精确地进入后续步骤。通常在这一阶段会生成数以百计的备选答案。
软滤波
在资源数量与回答精度的平衡中,一个关键步骤是轻量级的评分算法。这个方法会将数目庞大的初始备选答案缩减到一个合理的数量,然后才交给深度评分算法。比如,一个轻量级评分器可能会判断一个备选答案是否对应一个LAT。这一步称为“软滤波”。
DeepQA会将各种轻量分析的分值综合成一个软滤波得分。如果备选答案的软滤波得分超过了阈值,则会进入“假说及证据评分”阶段;否则直接进入“最终融合”阶段。
软滤波评分的模型和阈值是运用机器学习算法,通过不断训练得到的。Watson当前让大约100个答案通过软滤波,不过这个数字也是可以人为调整的。
假说及证据评分
通过了软滤波考验的备选答案将会经历一段非常严格的评估过程,包括收集额外的支持证据以及应用形形色色的深度评分算法来评估这些支持证据。
证据检索
一个极其有效的技巧:检索备选答案在主搜索中被发现时所在的那个段落。这将有助于找到原始问题的上下文。支持证据也可能存储在其他地方,比如三元组存储。
检索到的证据将进入深度证据评分模块,这个模块用来将备选答案放入支持证据的背景下进行评估。
评分
大量的深度内容分析就是在评分阶段实施的。评分算法会决定检索到的证据对备选答案的支持程度。DeepQA的架构支持并鼓励采用大量不同的组件和评分器,以便全面考察证据的不同方面;针对一个给定的问题,给出这个证据对备选答案支持得到底有多好。
DeepQA为评分器产生的假说(比如一个备选答案)和信心值提供了一个通用格式,但同时又对分数本身的语义做了一定限制;这使得DeepQA的开发者有能力快速部署、组合以及调整不同的组件来相互支持。Watson就包含了50个以上的评分组件,它们产生的分数类型从正式的概率分布到类属特征的数量不等,所基于的证据来源包括非结构化的文本、半结构化的文本以及三元组等。这些评分器考虑 一个段落的谓词-论元结构与问题的契合程度,段落来源的可信度,空间地理位置,时间关系,系统分类;备选答案的词汇和语义关系,和问题条目的互相关性,自身的普及性或者未知性、别称等等。
用这个例子可以一窥评分机制的部分机理:
问题“He was presidentially pardoned on September 8, 1974.” 意为“此人在1974年9月8日被总统特赦。”
- 注:尼克松(Nixon)因水门事件于1974年8月9日辞职,由福特(Ford)接任。福特在上任后一个月就特赦了尼克松在就职总统期间犯下的一切罪行。
正确答案“尼克松”是备选答案之一。在检索到的证据中包括了这样一句话:“Ford pardoned Nixon on Sept. 8, 1974”,意为“福特在1974年9月8日赦免了尼克松”。
第一种证据评分方法对比了这两句话中相同词语的数目。
第二种方法给出了两句话中最长的子字串的长度,“在1974年9月8日(on September 8, 1974)”一共4个英文词。
第三种方法度量了这两句话在逻辑形式(Logical Form)上的相似程度。逻辑形式是对文本的一种图形化摘要,图中的节点对应文中的词,图中的边对应文中的各种关系,包括语法关系、深度语义关系或者二者兼有。逻辑形式判定“尼克松”是“赦免”的宾语,而题目中问的内容恰恰就是“赦免”的宾语。逻辑形式判定给了“尼克松”在这个证据下的一个高分。
相对的,另一个备选答案“福特”在前两中方法中与“尼克松”得到完全相同的分数,但在逻辑形式判定中只能拿到一个很低的分数。
最终融合及排位
从问题中提取关键字并搜索相关文档是一回事,给出精确答案并对其正确性有足够准确的信心来下注就是另一回事了。赢得 Jeopardy! 的胜利需要后者的能力。
最终融合及排位的目的是基于当前的证据和数十万个评分,从几百种假说中找到一个最优的,并计算对它的信心--也就是正确的可能性。
答案融合
一个问题的不同备选答案可能形式各异,但含义相同。排位技术对利用备选答案的相对差异非常困惑。如果没有合并,排位算法会为了区别含义相同但形式不同的答案而无谓地浪费时间。
有一种研究认为如果发现了相似的备选答案,就可以提高他们的信心值。而DeepQA小组则观察到了这种现象:不同的表面形式通常会被不同的证据支持,并得到完全不同但潜在互补的分数。这产生了一种方法:将答案分数在排名和信心计算之前先合并掉。
在把匹配、标准化、共指消解算法整合在一起后,Watson可以识别等价或者相关的假说,比如“孙悟空”和“齐天大圣”,并将对应的特征相互合并来得到最终融合分数。其中“共指消解”就是对文章中同一实体的不同描述进行合并的动作。比如在本文中如果出现了“我”、“笔者”、“天蓝提琴”、“果壳网DIY主题站科技编辑”,则都是指的本文作者。人类可以毫无困难地分辨出共指现象,但计算机就需要专门的算法来解决这一问题。
排名和信心计算
在答案融合之后,DeepQA系统必须给假说排名,并且根据融合后的分数来估计信心值。
DeepQA系统采用了机器学习的方法来计算信心值:工程师们先准备一套已知正确答案的问题,让DeepQA来尝试给对应的备选答案评分。之后再查看这些备选答案的信心值,然后朝着缩小差距的方向调整参数再次评分,从而一步步训练出一个评分模型。