
想必大家最近都被12306坑爹的验证码刷屏了,在这紧张的抢票节奏里,还要忍受验证码对智商的考验,生活也真是不容易。
看到网站上的奇葩验证码,网友们纷纷献计献策,我个人觉得难度最大的应该是下面这种了:
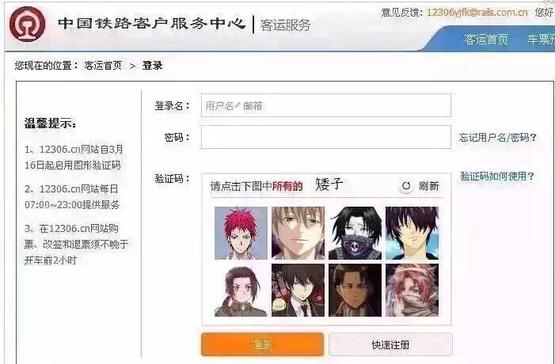 什么,你一个都不认识?图片来源:sinotf.com
什么,你一个都不认识?图片来源:sinotf.com
然而,吐槽归吐槽,在这小小的验证码背后,其实有着许多有趣的故事。屏幕上的方寸之间,其实有着智力上的激烈交锋。在验证码不断发展的背后,是一场场来势汹汹的技术变革。而这场变革,我们每个人都身在其中。
验证码的起源
想必很多人都觉得12306的验证码“反人类”,但其实,“反人类”的验证码最初是用来"反机器"的。
1998年,康柏电脑公司(Compaq Computer Corporation)的四位程序员马克·李李布瑞吉(Mark D. Lillibridge),马丁·阿巴迪(Martin Abadi),克瑞斯那·巴拉特(Krishna Bharat)和安德雷·布罗德(Andrei Broder)向美国专利局提交了一份专利。
在这份专利里,他们提出了一种选择性限制计算机系统访问的办法(Method for selectively restricting access to computer systems)。他们提出这个方法的主要目的,是为了防止脚本机器人(bot)自动向他们的搜索引擎提交网址。
在这篇专利里,他们采用随机生成含有字符串的图片这一方法来生成验证码,并通过扭曲外观和添加背景来避免图片被OCR(光学字符识别)技术破解。
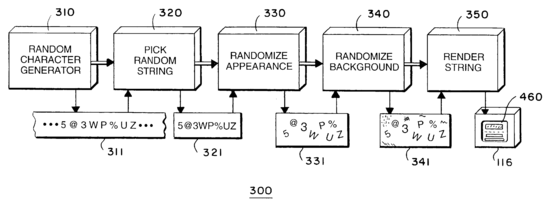 流程图:随机生成字符库→选取随机字符串→随机改变外观→添加背景→提交最终效果
流程图:随机生成字符库→选取随机字符串→随机改变外观→添加背景→提交最终效果
它就是验证码的雏形。
区分人与机器的验证码
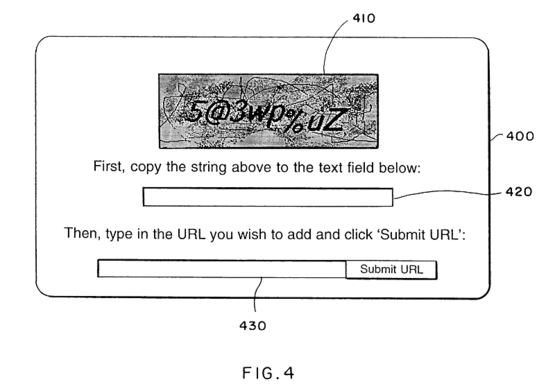
想必大家一定见过类似上面的验证码图案。而熟悉的验证码技术背后,隐藏的是这样一个很深奥的问题:
如何区分真人和机器?——即如何证明坐在电脑前的是一个活人而不是一段程序呢?
在这个问题上,一种解决方案是“图灵测试”,即“人类向计算机提问”。而验证码恰好相反,是“机器提问人类解答”,因而验证码也被认为是“反图灵测试”。
2003年,路易斯·冯·安(Luis von Ahn)等人提出了“全自动区分计算机和人类的公开图灵测试”,即CAPTCHA(Completely Automated Public Turing test to tell Computers and Humans Apart)。
这个短语,正是验证码的名字。
而这就引发了一个新的问题:机器人向人类提出的问题,能让机器人解答吗?如果机器人能够识别验证码,那不是意味着这个验证码不再能够验证“人类”和“机器”了?
从这以后,各种各样的验证码和验证码破解层出不穷,程序员们的创意和才智在这方寸之间得到了尽情的发挥。而我们,也终于有幸体验到了买火车票之艰难。
程序员们智力的角逐
早期的验证码可能只是一串简单的ASCII字符,比如黑客们用
|-|3|_|_()
)-(3££0”
代表“HELLO”。这个后来发展成了火星文(leetspeak),o(╯□╰)o。
后来验证码变成了图片显示字符串或者数字的形式,这也是我们最常见的验证码。

早期的验证码采用扭曲字符和梯度背景,然而好景不长,这样的验证码很快就被破解了:
由于图片中字符与背景颜色之间差异较大,于是程序员们可以利用算法将图片中的每一个像素点的值提取出来,然后判断哪些是背景部分,哪些是字符部分。这样将字符与背景分离。
接着,将分离出来的字符与“训练库”——也就是存有这些字符的资料库——里的字符进行最终识别。而且由于英文只有26个字母,而阿拉伯数字只有10个,这样的验证码识别难度也大大降低。
如果一切顺利,根据上面的流程计算机能很容易地识别验证码,并不需要人。这个验证码,也就被破解了。
于是,喜闻乐见的,我们迎来了中文验证码,庞大的中文字符库保证了验证码识别的难度(还混用了拼音):
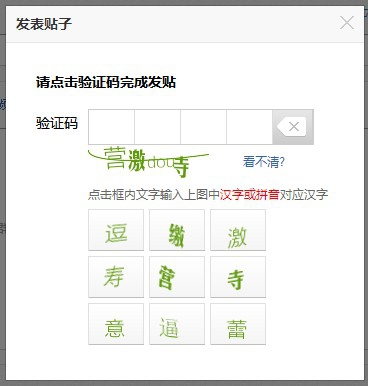
而不会中文的歪果仁则开始逆向思考验证码识别技术并进行针对性的对抗。他们把各个字母粘连起来,这增加了算法上分隔每一个字符的难度。并且每次采用不同的字体也能增加模式匹配的难度。
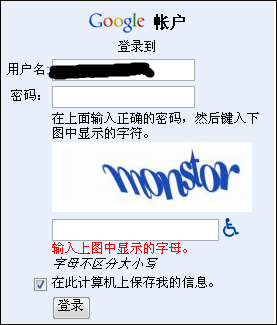
而到了12306这个程度,考验的就不单纯是图案识别了,还有某些抽象思维的能力——比如我得知道“紫砂壶”到底是个啥,或者至少知道它长啥样,我才能选到正确的验证码图案。这,也就是我们俗称的“智商”……

然而,这样的图片验证码也并不是一劳永逸的,有人展示了用网络上的识图算法来机器识别12306图片验证码的一种思路。原理大概是这样的:首先将验证码的图片分割成一个个单独的图片,然后将这些图片上传到机器识图的网站上,网站会返回下面的答案。
 图片来源:zhihu.com
图片来源:zhihu.com
接着,只需要让机器识别出验证码的“问题”,也就是需要点击的图片是什么“东西”——在这个例子里是“紫砂壶”——最后让计算机一一匹配就可以了。
并且他认为12306的这一方法其实并不靠谱,存在三个问题:
1、图片过于复杂、混淆过多、条件太诡异时会挡住大部分正常用户
2、容易被枚举,题库太弱,不如字符组合可能性多
3、破解门槛不一定高于字符型Captcha
对于这个分析,我举双手双脚赞成。我买不到票不是智商低,而是因为我们属于被挡住的“大部分正常用户”,嗯,一定是这样的。
然后现在, 铁路总局已经表示,12306网站将调整图形验证码中图片的清晰度和分辨率,而且可能剔除根据后台统计出来大家反映最多的和错误率较高的图片验证码……
更多的……验证码?
当然,还有一些更奇葩的验证码。这些验证码已经变成了一种游戏,而不是单纯的为了区分人类与计算机了:
 输入正确的验证码就可以将图片中的码去掉……图片来源:ticbeat.com
输入正确的验证码就可以将图片中的码去掉……图片来源:ticbeat.com
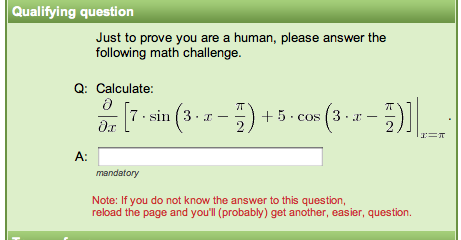 我的数学是体育老师教的,你们呢?图片来源:buzzedtip.com
我的数学是体育老师教的,你们呢?图片来源:buzzedtip.com
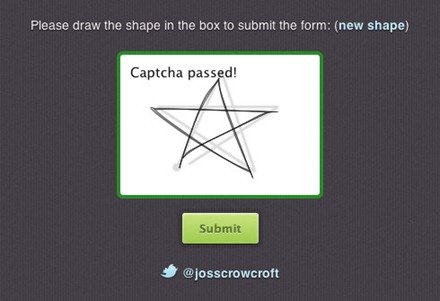 会画画,走遍天下都不怕……然而手残怎么办?图片来源:twitter
会画画,走遍天下都不怕……然而手残怎么办?图片来源:twitter
面对越来越复杂的验证码,算法可能捉襟见肘,然而还有一种万能的破解方式,那就是:人工识别(Cheap or unwitting human labor)。即将验证码分发给分布式的客户端,客户端人肉识别,返回结果。
还有人专门开发了客户端软件,让没事干的大学生人肉识别验证码赚些小钱。如果在线人数足够多,任务下达后几乎都是秒回的,效率也是不错的。所以,识别好验证码也是一项赚钱的技能(大雾)。
验证码还能干啥?
验证码也并非都是那么奇葩,它也可以用来做一些非常有意义的事情。
例如:卡耐基梅隆大学的路易斯·范安等人(对,就是前面提到的造出CAPTCHA这个短语的人啦)设计了一个名叫 reCAPTCHA 的系统,来进行古籍的数字化。
reCAPTCHA将 OCR(光学字符识别)软件无法识别的文字扫描图传给世界各大网站,用以替换原来的验证码图片;那些网站的用户在正确识别出这些文字之后,其答案便会被传回卡耐基梅隆大学。
reCAPTCHA 在 2009 年被 Google 收购,而Google将这一技术发扬光大,不仅用来识别古籍,还用来识别Google街景的街道地址。所以,有一段时间,你会发现google 的验证码变成了某个门牌或者路标:
 谷歌的验证码有时候是街景拍到的门牌号。图片来源:tumblr.com
谷歌的验证码有时候是街景拍到的门牌号。图片来源:tumblr.com
验证码的未来
“反人类”的验证码,从始至终对抗的就不是人类,而是有着庞大计算能力却在模式识别、抽象思维上很弱的计算机。
然而,随着人工智能技术的进步,计算机在模式识别上也越来越强大,验证码也不得不走上越来越“扭曲”、“复杂“、“反人类”的不归路。验证码难度的提升,本质上反应了人工智能技术的进步。
而目前,无论我们多么吐槽12306的验证码,但至少,我们还能够通过它证明我们是真人,而不是机器。这在某种程度上反应了人类在智能上的优越性,至少现在,我们还是比机器智能优越。(或许有一部分小伙伴没法证明?)
目前,Google的算法在扭曲文本类验证码的识别率已经达到了99%,也就是说,这类验证码已经不能作为区分人类和机器的指标了,而总有一天,12306的验证码也会被破解,到那时,为了区分机器和人类,程序猿们又该设计出什么样的验证码呢?
验证码的一生,可以说正是人工智能技术不断进步的一生。而正因为机器越来越聪明,所以人类将不得不面对更多的挑战。或许有一天,人类的造物终将超越人类自己,人工智能终将超越人类,到那一天,验证码或许不复存在了,而人类又该何去何从呢?(编辑:Jerrusalem)
本文由十五言的科学写作训练专栏“科学人的秘密发动机”孵化而成。欢迎科学写作同好加入其中。