
“当时,我独自一人在格宁根大学给我的豪华办公室里……我打开研究数据的文件,将一个不符合我预期的数字2改成了4……我看了一下办公室的门,它是关着的….我看着数据,点击鼠标完成了对数据的统计分析。当我看到新结果时,整个世界都回到 ‘合乎逻辑’的状态。” ——Ontsporing,德里克·斯塔佩尔
德里克·斯塔佩尔(Diederik Stapel)曾经是社会心理学界闪亮的学术之星。他的研究有趣且简单,数据也总能让人眼前一亮。但是,2011年下半年,他被研究生举报数据造假。随后的调查发现,他可能是心理学界造假最多的人:55篇论文的数据造假,其中许多研究根本就没有进行!2011年上半年,他在《科学》上的一篇文章中描述到:“实验在乌特勒支火车站进行,我们在火车站随机找到一些志愿者来参加实验,邀请他们坐下来填写一份问卷,他们可以从一排六个椅子中选择一个坐下”。但乌特勒支火车站根本没有这么“六个椅子”。
 讽刺斯塔佩尔谎话连篇的漫画。图片来源:Marco Lap/www.kijkmagazine.nl
讽刺斯塔佩尔谎话连篇的漫画。图片来源:Marco Lap/www.kijkmagazine.nl
身败名裂的斯塔佩尔在痛苦之中将自己造假的全部经历写出来,并以“Ontsporing”(荷兰语,意为脱轨)一词作为为书名出版,于是才有了我们在上面看到的这一段文字。
在人类社会中,欺骗行为人人喊打,却又无处不在。回顾一下最近几年的新闻,从学术界的斯塔佩尔、体育界的阿姆斯特朗到金融界的麦道夫,再到娱乐圈沸沸扬扬的出轨消息,我们可以找到各式各样的欺骗行为。为什么行骗之人能够如此大胆?仔细探寻,你也许会发现,这些弥天大谎里的不少案例,都是从非常小的事件开始的。
一旦开始做某件坏事后就无法停止,并且最后滑向无法收拾境地的情况,被学界称为“滑坡效应”(slippery slope)。虽然这个社会现象很早就被人们注意到,但人们却从来没有探索过在这个过程背后,大脑是如何进行反应的。前一阵子,英国伦敦大学学院的研究者尼尔·加勒特(Neil Garrett)、斯蒂芬妮·拉扎罗(Stephanie C Lazzaro)、 塔莉·夏洛特(Tali Sharot)和美国杜克大学的研究者丹·艾瑞里(Dan Ariely)一起探索了这个问题,并将结果发表在了《自然-神经科学》(Nature Neuroscience)杂志上 [1]。
欺骗别人时,你感受到自己的情绪了吗?
欺骗行为是普遍受到人们谴责的。因此,当一个正常的个体对他人进行欺骗时,施骗者内心总有一些情绪的反应,可能表现为紧张、害怕等。这些情绪也许不都会表露在行骗者的脸上,但可能表现为一些内心的感觉、生理活动的变化以及神经活动的变化。
对于正常人来说,说谎带来的情绪往往并不让人愉快。这也许能给人们真诚相待提供帮助——如果不想被不好受的感觉困扰,人们可能就会减少说谎。实际上,有研究者发现,如果给人们一些镇定剂抑制他们的情绪反应,他们说谎的可能性会变得高一些[2]。
只可惜,情绪反应与人类的其他认知活动一样,都会在重复的刺激下迎来适应。正如“入鲍鱼之肆久而不闻其臭”,反复浸没在自己的谎言之中,人们是不是就不会再有强烈的情绪反应了?如果说谎时的情绪随说谎次数的增多而减弱或者消失的话,人们说出更多的谎言或者更大的谎言就不足为奇了。为了探究这种可能性,加勒特等人在实验室里研究了人脑对对谎言的适应过程。
为了自己获利,谎言可能越扯越大
虽然欺骗行为很容易定义,但是在实验室去研究人们的欺骗,总有一个硬伤:如何让参与者在真正意义上说谎,而不是根据研究者的指导语去说谎?加勒特等人想出了一个巧妙的方法:他们让每个实验参与者参与到一个“估值任务”当中,并告诉参与者,他/她将与另一人进行合作。参与者会看到一罐子硬币的图片,罐子里面装着一堆1便士的硬币,大约是1500个到3500个之间。参与者需要自己估计出罐子里的钱数,然后告诉另一个人(研究者安排的“内应”)。
研究人员让参与者相信,另一个人看不到这一罐子硬币的图片,只能根据参与者提供的信息对罐子里的钱数进行最终评估并上交给实验员,而实验员将根据这个评估的结果对实验中的两人进行奖励。这就给了参与者可以撒谎但不被发现的机会。
 在一轮又一轮的测试中,参与者都可以在给出自己的估计时夸大其词。为了了解参与者在做出诚实估计时的极限水平,研究者另外设置了一个“估计得越准确,参与者最终获得的奖励越多”的分组。图片来源:参考文献[1]
在一轮又一轮的测试中,参与者都可以在给出自己的估计时夸大其词。为了了解参与者在做出诚实估计时的极限水平,研究者另外设置了一个“估计得越准确,参与者最终获得的奖励越多”的分组。图片来源:参考文献[1]
为了操控参与者说谎的动机,加勒特等设置了不同的奖励规则:既有“损人利已”的条件,即猜测的数目越大,则奖励给参与者的钱越多,但给另一方的钱越少;也有“利人利已”的条件,即猜测的数目越大,给参与者与另一方的奖励越多。当然,反过来,也有损己利人的情况——在另一个分组中,参与者猜测的数目越大,参与者自己就越亏。
55名成年人参与了这项实验,每个参与者需要进行60次上述的决策,但实验结束后的奖励,将从这几十次决策中选择一次来作为给他们的奖励。这种设置一方面可以给研究者省钱(如果一次就奖赏15到35镑,一个实验下来花费就快2000镑了!),另一方面,由于没有奖励的累积,所以参与者在实验后期出现说谎尺度更大的情况,就可能不是由于金钱的奖励,而是确实是习惯了说谎——毕竟谁也不知道最后抽中的是哪一次,在实验的后期说谎与在前面说谎可能带来的奖励是没有差别的。
研究者发现,如果说谎能对自己带来好处——无论是利人利己还是损人利己——随着实验的进行,参与者说谎的尺度都会越来越大。但是说谎对自己没有好处时,谎言不会随着时间变化。
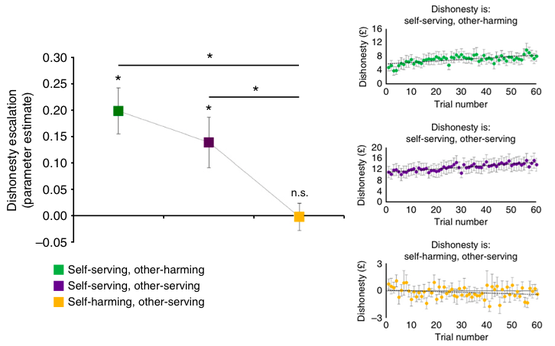 左图:不同条件下,谎言尺度增加的平均值。绿色(损人利己)和紫色(利人利己)代表的是两种对参与者自己有好处的条件,这两种条件下,谎言尺度增加的程度明显高于0,而在黄色所代表的条件(损己利人)下,则与0没有差别。右图:三种条件下,参与者不诚实的程度(英镑数)随测试轮数的变化。图片来源:参考文献[1]
左图:不同条件下,谎言尺度增加的平均值。绿色(损人利己)和紫色(利人利己)代表的是两种对参与者自己有好处的条件,这两种条件下,谎言尺度增加的程度明显高于0,而在黄色所代表的条件(损己利人)下,则与0没有差别。右图:三种条件下,参与者不诚实的程度(英镑数)随测试轮数的变化。图片来源:参考文献[1]
反复的欺骗中,大脑的情绪反应发生了适应
在小谎变大谎的过程中,参与者的大脑做出了怎样的反应?25名参与者在核磁共振仪中完成实验,结果提示随着实验的进行,他们的大脑对说谎产生了适应。
神经科学的研究已经发现,大脑中杏仁核的活动与情绪反应(尤其是消极的情绪反应)密切相关:情绪反应越强烈,杏仁核的活动越强烈。反过来,杏仁核的活动越强烈,大部分时候也是因为人们的情绪反应越强烈。研究者发现,随着实验的进行,当参与者慢慢习惯欺骗时,负责情绪加工的脑杏仁核在说谎时活动强度发生了减弱,
加勒特等人对杏仁核活动减弱的程度和说谎尺度增加的程度进行了分析,发现了一个有趣的趋势:在利己的条件下,如果参与者这一次说谎时,杏仁核的活动相比上一次说谎时有所减弱,那么在下一次说谎的时候,TA说谎的尺度可能比这一次会增加。
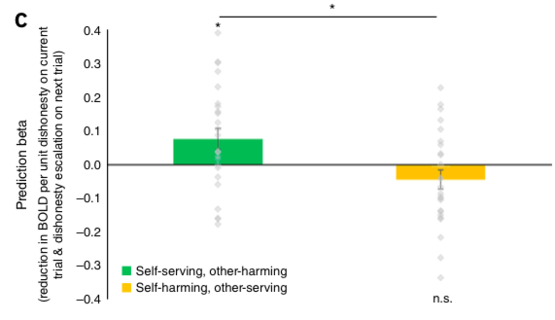 杏仁核在不诚实条件下活动信号减弱程度与谎言增大程度的相关。说谎对自己有利的情形下,当前杏仁核活动减弱与下次说谎尺度增加之间的关系,在统计上是大于0的。在损己利人的条件下则观察不到同样的效应。图片来源:参考文献[1]
杏仁核在不诚实条件下活动信号减弱程度与谎言增大程度的相关。说谎对自己有利的情形下,当前杏仁核活动减弱与下次说谎尺度增加之间的关系,在统计上是大于0的。在损己利人的条件下则观察不到同样的效应。图片来源:参考文献[1]
这些结果证实了人们的直觉:小的错误可能会慢慢‘升级’为严重的错误。更重要的是,他们的研究发现,在这种升级的过程中,情绪可能起了一定的作用,这作用可能反映在杏仁核的活动减弱上。
如果上述结果能够得到进一步实验的验证,研究者也许可以通过测量人们说谎时杏仁核(和/或其他情绪加工的脑结构)的活动,可以预测他今后说谎的尺度。当然,能够这么使用的前提是,人们在现实生活也会像参与实验一样地真实,因为测谎的技术在反测谎策略前,往往是很脆弱的。
但至少,这一发现从神经科学角度给人们敲响了警钟:如果一个人对小谎小骗不以为意而常常为之,也许有一天,他终将若无其事地撒出弥天大谎。
(编辑:Calo)
参考文献:
- Garrett, N., Lazzaro, S.C., Ariely, D. et al. The brain adapts to dishonesty. Nat。 Neurosci, 2016, advance online publication.
- Schachter, S. & Latané, B. Crime, cognition, and the autonomic nervous system. In Nebr. Symp. Motiv. 12 (ed. Levine, D.) 221–275 (1964).