
许多微博文本里头都有个链接。什么样的链接你会忍不住手滑去点?点完了又忍不住手滑去转发?今年早些时候,国外就有科学家做过这样的研究,略有不同的是,他们没有微博,只有推特。
今年 2 月初,惠普研究所的 Bernardo Huberman 和加州大学的 Roja Bandari 等人发表了一篇论文,提出了一种预测一篇文章流行程度的方法。研究人员通过找到一种算法,仅仅根据文章的内容就推断出文章 在被分享到推特后会获得多少点击和转发 ,而该算法准确率据说高达 84%。这一研究无疑引起了广泛的关注,国内外众多科技新闻网站都曾有报道。如此神奇的研究结果是如何获得的?它真的靠谱吗?不妨就让我们来一窥究竟。
流不流行,推特说了算
很显然这是一个基于统计分析的研究。我们知道, 所有基于统计分析的研究,它的样本都是非常关键的 。研究者通过一个叫做 Feedzilla 的应用程序收集了 2011 年 8 月 8 日到16日之间,某些新闻汇集网站上的 4 万多篇文章。Feedzilla能够记录并整理统计这些文章的摘要、地址、标题、时间以及 被分享到推特上的次数 。
而得到的这些数据将用于模型的训练和测试(这两个概念我们会在之后详细介绍)。另外为了使一些参数尽可能准确,研究者在确定某些参数时采用了更大的样本空间。
另一方面,被分享到推特上的推文传播量则可以通过搜索引擎查询出来。有研究表明推特上的推文转发量会在 4 天左右达到平台期,也就是转发量基本不再增加。因而研究者就把转发量被定义为该条推文在推特中传播 4 天时的总转发量。
需要强调的是,研究者想要解答的问题是“如何在一则文章被发出前就判断它是否会流行”。为了降低研究难度,他们抛弃了一些现在还无法处理的不定因素,因此 研究对象只是推特上各种相关信息中的一个子集 。具体说来就是, 它不是一条随机取出的某个推友(关于某篇样本文章)的原创推文,而必须是从新闻汇集网站分享到推特上的一则信息 。分享的内容包括新闻、博文、专栏评论等等。
影响流行程度的4个要素
在了解上面这些基本信息后,我们再来看一下研究者的基本思路:
确定文章内容的关键因素。 统计这些关键因素取不同值时对文章流行度的影响,并将各取值赋以不同分值。 利用统计方法建立并优化“内容关键因素”对“流行度”影响程度的数值模型。 利用模型预测某篇文章在推特上的流行度。
在这篇论文中,作者选取了4个判断的关键要素,并为每一条样本推文按照这4条要素打分。它们分别是:
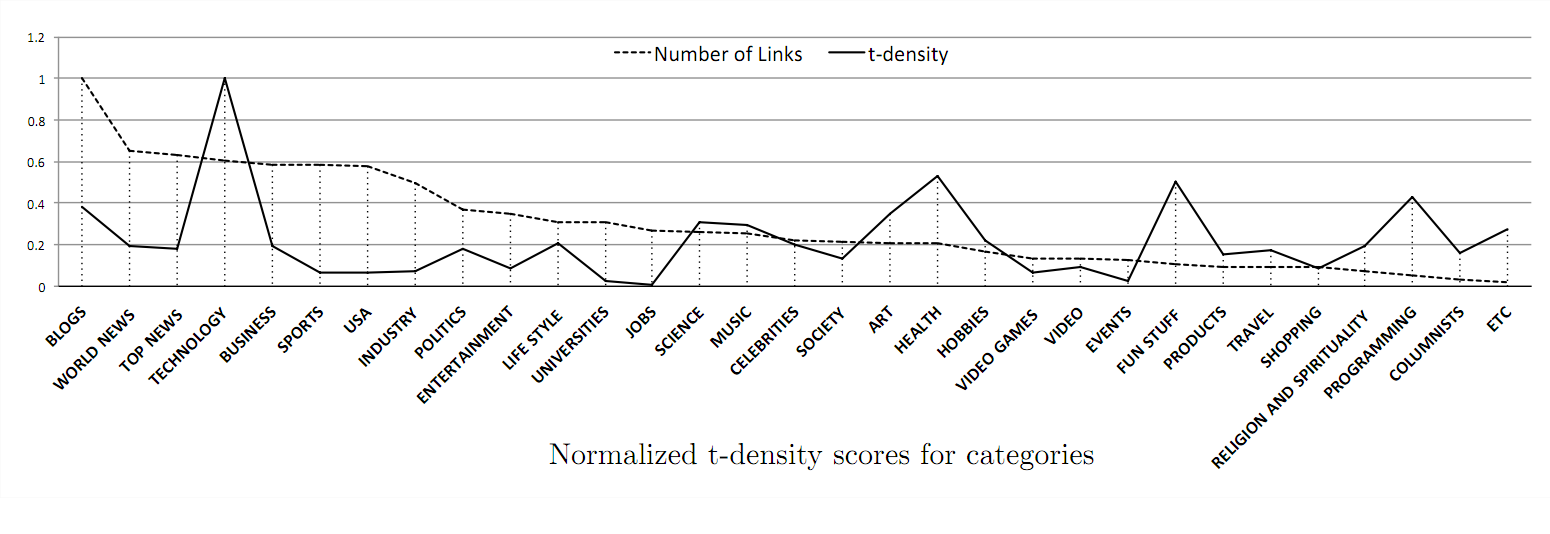
信息类别。 下图中的虚线表示不同类别的推文包含的连接(指向文章)数量,实线表示平均每一个链接被转发的次数(t-density)。从中可以发现科技类的信息虽然数目上不是最多,但很受推友的青睐,而求职或招聘类信息的流行度就不高。研究者将获得的 4 万条推文分成两个部分,前一半用于计算不同信息类别的t-density,并用其为各种信息类别的流行度打分。
客观程度。 一篇文章所使用的表达方式是否会影响到其受欢迎的程度?要获得更多转发,是做一个标题党用上情绪化的描述,还是实事求是用平实客观的语言表达?在不知道结果之前,这当然也应该被当做一个要素来考虑。研究人员用软件判断样本标题及摘要的客观程度,并为其设定分值 0 或者 1。为了提高模型的准确性,他们将传统上认为非常客观及非常主观的广播及电视节目稿输到程序中进行优化,最终达到了 99% 的准确度。
提及的人物和地名。 在推文中提及一些著名的人物(比如姚晨)、有趣的地方(比如海南)会不会提升这条推文的受欢迎程度?研究人员先使用标签提取工具把样本标题及摘要中提到的人名及地名提取出来,然后分析包含不同标签的推文所获得的t-density。由于一条推文可能提及多个人名和地名,因此在模型中可以使用 3 种不同的分值:标签的总数、标签的最高分值或标签的平均分值。
新闻来源。 本项研究中采集的推文来自 1350 个不同的信息源,不同的信息源是否会带来不一样的人气?比如人民网发布的消息会不会比某个不知名博客发布的更受欢迎?研究者把样本信息扩大到 50 天内的数据,并求出了它们的 t-density。
如何预估流行度
搞定上述的4 个关键要素后,就可以去推算最终结果了。社会网络的传播学研究一定要遵从基本的统计学方法。一般来说要通过统计方法建立一个数值模型,必须将原始数据中的一部分数据用于训练(training),然后用另一部分数据用来测试(testing)。只有当测试误差值小于一定数值,才能认为这个模型用于预测。
研究人员经过计算,得到一个挺简单的公式:
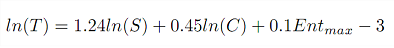
其中 T 是一条推文的流行度(即t-density),S与C分别代表不同信息来源及不同信息类别的 t-density 分值,En t max 为待测推文提及的人名或地名中的最大t-density值。这个公式被很多海外科技报道归纳为:来自可靠的信息源、提及名人并且谈论流行话题(比如科技、健康)的文章倾向于可以获得更多的点击及转发。而令人意外的是,表达方式的客观与否在传播效力上并不会带来明显的差别,所以总想着标题党的同学可以休矣了。
但实际上,这个预测的误差还是比较大的。所以原文还给出了一个改进算法,不过这个算法其实只与信息来源及所提到的人名或地名标签有关。研究者认为将预测限定于特定的类别(比如科技类信息)能进一步提高预测的成功率,因为不同类别信息之间多有重叠,这可能带来了不小的统计误差。
很多国内外的新闻网站在介绍这篇文章的时候都笼统地说这一研究结果对于新闻在推特上流行度的预测能够达到 84% 的准确率。这里要强调一下, 84% 的准确率并非指的是流行度的准确数值,而是它的档次 。原文把流行度依据转发数量分成了三档,1-20次算是低流行度、20-100次的算作中等流行度,100-2400次的被认为是高流行度。
终上所述,这 4 个判断依据还不足以精准地预测一条以分新闻内容的推文能被转多少次,但模型能够对这篇新闻报道是否能流行起来做出比较准确的估计。这确实是个很有意思的研究,也许你也可以在微博上留意或者实验一下。 不过本文的研究对象有一定的局限性,值是各类通过“分享”新闻报道形成的推文 。而且推特和微博无论从技术还是参与者来说都还是有所不同的,所以它未必能够直接套用到微博中。此外对于社会网络传播现象的数学研究还处于初起阶段,数据分析的方法不算特别完善。但最后真正要提醒的是,掌握这些要素固然能使你的文章更流行、更多人“手滑”点击了微博上的那个链接,不过说到底,内容的好坏才是评价一篇文章质量的关键。
参考资料: The Pulse of News in Social Media: Forecasting Popularity