
 我们已经创造了一种全新的智能形式,尽管没有人能够看透它如何思考、如何推理。图片来源:extrahype.com
我们已经创造了一种全新的智能形式,尽管没有人能够看透它如何思考、如何推理。图片来源:extrahype.com
(文/ Douglas Heaven)瑞克·拉希德(Rick Rashid)这么紧张是有原因的。他在中国的天津迈上讲台,面对2000名研究者和学生,要发表演讲。问题在于,他不会讲中文,而他的翻译以前糟糕的水平,似乎注定了这次的尴尬。
“我们希望,几年之内,我们能够打破人们之间的语言障碍,”这位微软研究院的高级副总裁对听众们说。令人紧张的两秒钟停顿之后,翻译的声音从扩音器里传了出来。拉希德继续说:“我个人相信,这会让世界变得更加美好。”停顿,然后又是中文翻译。
他笑了。听众对他的每一句话都报以掌声。有些人甚至流下了眼泪。
这种看上去似乎过于热情的反应是可以理解的:拉希德的翻译太不容易了。每句话都被理解,并被翻译得天衣无缝。令人印象最深的一点在于,这位翻译并非人类。
曾几何时,执行这样的任务远超最复杂的人工智能的能力,而且并不是因为人们没有为此付出努力。多年以来,人工智能领域被那些旨在复制人类意识功能的宏大计划统治着。我们梦想着拥有一台机器,能够理解我们、识别我们,帮助我们做出决定。近几年来,我们已经实现了这些目标,然而实现的方式,是先行者不曾想象的。
如此说来,我们已经研究出了复制人类思想的方法了吗?还差得远呢。相反,实现这些目标的方法,与我们最初的愿望大相径庭。人工智能在你周围无处不在,它的成功可以归因于大数据和统计学,也就是利用海量信息执行复杂计算。我们已经创造出了意识,只不过它们与我们的意识相去甚远。它们的推理过程,对人类来说深不可测——这一进展所预示的前景,正在引起人们的关注。既然我们正在愈加依赖这种新型智能,我们或许需要改变自己的思维方式去适应它。
复制思维
半个多世纪以前,研究者列出了一系列目标,是我们向具备类人智能的机器挺进时必需要达成的。英国布里斯托尔大学的尼洛·克里斯蒂亚尼尼(Nello Cristianini)说:“从上个世纪50年代开始,我们就有了一张待办事宜的清单。”他曾写过人工智能研究历史和演化方面的著作。
清单上的很多项目可以追溯到1958年在英国特丁顿召开的思想过程机械化会议。参与那次会议的,不仅有计算机科学家,还有物理学家、生理学家和心理学家。按照我们的样子建造思考机器的前景,令这些人全都激动万分。他们一致认为,智能的特征应该包括对理解话语、翻译语言、识别图像,以及模仿人类决策的能力。
然而时间在流逝,那张清单却丝毫没有变短。很多研究者试图以逻辑公理为根基,使用程序化的规则来模拟人类思考。他们以为,只要创建足够多的规则就能成功。但事实证明,这太难了。几十年过去了,人工智能研究成果寥寥,资金告罄。
那么,究竟是什么发生了改变呢?“我们并没有找到智能的解决方案,”克里斯蒂亚尼尼说,“我们算是放弃了。”然而,这便是突破。“一旦我们放弃制造精神和心理特性的尝试,成功之道便开始出现在眼前了。”
说白了,他们放弃了预编程的规则,而是投向了机器学习的怀抱。利用这种技术,计算机教会自己从数据中建立模式。有了足够大的信息量,你就能让机器学会做看上去有智能的事情,别管是理解话语、翻译语言,还是识别人脸。英国剑桥微软研究院的克里斯·毕肖普(Chris Bishop)打了个比方:“你堆积足够多的砖块,然后退上几步,就能看到一座房子。”
这种方法的原理大概是这样的。很多最成功的机器学习系统,依据的都是贝叶斯统计,这种数学框架能让我们测算可能性。根据给定情境以及先前在类似情境中观察到的关联数据,贝叶斯统计能够给出出现某个结果的可能性数值。
比如,我们想让人工智能回答与一个简单问题:猫吃什么。基于规则的方法要从零开始,采取有逻辑的步骤,建立一个关于猫及其饮食习惯的数据库。采用机器学习技术,你只需要不加选择地输入数据——互联网搜索、社交网络、食谱书籍等等。通过计算特定词汇出现的频率,以及概念之间如何彼此关联,系统便建立了一个统计模型,能够估计猫喜欢某些食物的可能性。
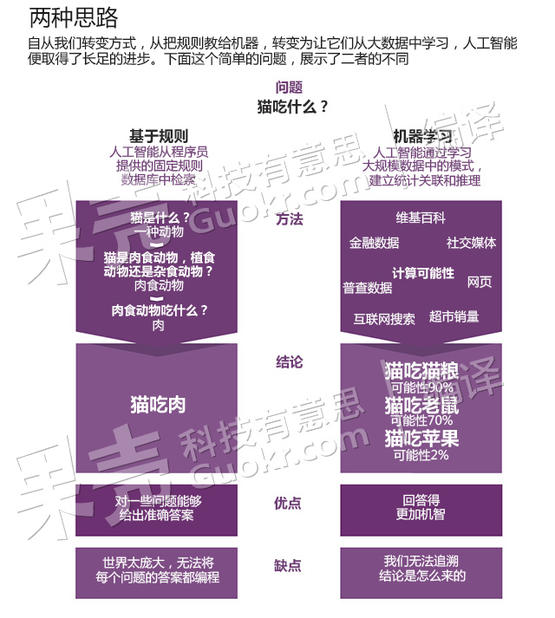 在人工智能的发展道路上,人们采取过两种截然不同的途径。图片来源:《新科学家》
在人工智能的发展道路上,人们采取过两种截然不同的途径。图片来源:《新科学家》
当然,机器学习所依赖的算法已经出现多年。新鲜之处在于,现在我们有了足够的数据,让这种技术大显神威。
就以翻译语言为例。20世纪末,IBM将加拿大国会生成的英法双语文档输入计算机,利用机器学习技术教它在这两种语言之间互译。那些文档就像罗塞塔石碑一样,包含了几百万被写成两种语言版本的例句。
IBM的系统辨别出两种语言单词和短语之间的关联,并将这种关联应用于新的翻译任务。结果却满是错误。他们需要更多的数据。“这时谷歌跟了上来,差不多输入了整个互联网,”英国牛津大学互联网学院的维克托·迈尔-舍恩伯格(Viktor Mayer-Schönberger)说道。
和IBM一样,谷歌在翻译领域所作的努力,一开始也是发展算法,在多语言文献之间交互参考。然而,研究者开始意识到,如果翻译器学习了说俄语、法语和韩语的人们实际的讲话方式,翻译质量将有很大提高。
谷歌转向了被它索引过的庞大网络。这张网络正在朝豪尔赫·路易斯·博尔赫斯(Jorge Luis Borges)1941年的短篇小说《巴别图书馆》中那座假想的图书馆迅速演进。小说中的图书馆收藏的书籍,囊括了所有可能的词语组合。假设谷歌翻译器正试图将英语翻译成法语,它便可以将它最初的尝试与互联网上用法语写就的每一个句子作比较。迈尔-舍恩伯格用翻译“light”一词来举例:表示光照时,要翻译成法语词“lumière”,表示重量时,则要翻译成“léger”。谷歌翻译器自己学会了如何做出与法国人一致的选择。
除了大量词序的相对频率,谷歌翻译器,以及拉希德使用的微软翻译器,对语言可谓一无所知。这些人工智能无非是一个词接一个词地计算接下来出现什么词的可能性。对它们而言,这只是个概率问题而已。
这些基本原理多少显得有些直来直去。当巨量数据中产生海量关联时,事情就复杂了。比如,谷歌的自动驾驶汽车,为了对周围环境作出预测,每秒钟要收集差不多1GB的数据。亚马逊这么善于诱导人们购买更多的商品,是因为它做出推荐所依据的基础,乃是几百万其他购买行为中的几十亿关联关系。
大者为王
翻译拉希德的演讲,展现了统计人工智能可以有多么强大——不仅要猜测他说了什么,思考该怎么翻译,还要判断这句中文由他说出来是什么效果。“这些系统的表现并非神迹,”毕肖普说,“但仅仅是探究一下巨量数据的统计信息,就能取得这么大的成就,我们常常为此感到惊讶。”
这些智能算法正开始影响生活的每一个方面。就在拉希德演讲一个月之后,荷兰国家法证科学研究所就雇了一套名叫波拿巴(Bonaparte)的机器学习系统,辅助他们寻找一名已经潜逃了13年的谋杀犯罪嫌疑人。波拿巴能够分析和比对大量DNA样本,这个工作由人工来做的话将非常耗时。保险和信用行业也在拥抱机器学习,部署这种算法为个人建立风险评估简况。医学界也在利用统计人工智能,筛选大得令人类无法分析的基因数据库。IBM公司的沃森(Watson)甚至能够诊断疾病。
“大数据分析能够发现被我们遗漏的事情,”迈尔-舍恩伯格说,“它对我们的了解,比我们自己还要深刻。但它也需要一种迥然不同的思考方式。”
在人工智能发展早期,“可解释性”被赋予了很高的价值。当机器做出选择时,人类能够追查到原因。然而,如今,那些由数据驱动的人工意识所做的推理,是对巨量数据点进行高度复杂的统计分析。换句话说,为了得到“是什么”,我们放弃了“为什么”。
就算一位高超的技师能够搞懂其中的数学过程,可能也没有什么意义。毕肖普说,那并不会揭示为什么系统会做出某个决定,因为这个决定并不是经由人类能够解读的一系列规则而得出的。他认为,为了得到有用的系统,这是个可以接受的取舍。早期的人工意识或许是透明的,但它们都失败了。“你可以得到一个解释,但那是对错误预测的解释。”一些人对这种转变提出了批评,但毕肖普和其他一些人主张,是时候放弃对人类解释的期待了。
“可解释性是一种社会契约,”克里斯蒂亚尼尼说,“过去我们认为它很重要,现在我们认为它不重要。”
英国布里斯托尔大学的彼得·弗拉赫(Peter Flach)试图向他计算机科学专业的学生,讲授这种从根本上不同的思维方式。编程讲究绝对,机器学习分析的却是不确定程度。他认为,我们应当更习惯怀疑。比如,亚马逊的人工智能推荐了一本书,这究竟是机器学习的结果,还是亚马逊有一些书不好卖?再比如,亚马逊可能会告诉你,和你差不多的人购买了它所展示的书,它所说的“和你差不多的人”以及“与此差不多的书”究竟是什么意思?
“也许,在某种程度上,我们终将不得不信任机器,即便我们无法完全理解它,”弗拉赫说。
危险在于,我们不再提出问题。我们会习惯于在不经意间由机器替我们做出决定吗?由于智能机器已经开始针对抵押申请、医疗诊断,甚至你是否有罪,做出神秘莫测的决断,我们押在人工智能上的赌注更大了。
比如在医疗方面,如果一套机器学习系统认为,你在未来几年中将开始酗酒,会怎么样?医生可以据此拒绝给你施行器官移植手术吗?如果没人了解结论从何而来,便很难讨论你的病情。一些人可能会信任人工智能甚于其他。“人们太愿意接受算法发现的事情,”弗拉赫说,“连计算机都说‘不’了。而这正是问题所在。”
此时此刻,某个地方,可能有一部智能系统正在判断你是什么样的人——以及将成为什么样的人。看看发生在美国哈佛大学拉坦娅·司维尼(Latanya Sweeney)身上的事情吧。有一天,她惊讶地发现,她的谷歌搜索结果附带的广告问道“你被逮捕过吗?”白人同学的搜索结果中却没有这条广告。这件事促成了一项研究,表明谷歌搜索背后的机器学习系统,无意中成了种族主义者。在深不可测、浩若烟海的关联当中,跟犯罪纪录相关的广告与黑人更常使用的名字被联系了起来。
“人工智能会遇到很多伦理困境,”迈尔-舍恩伯格说。很多人已经对大数据时代的隐私问题表达了关切。 “说实话,相对于隐私,我更担心统计预测遭到滥用。”
 我们已经建造的标志性智能系统,不像先驱者当年设想的那样,是一个能够思考的机器。图片来源:raymazza.com
我们已经建造的标志性智能系统,不像先驱者当年设想的那样,是一个能够思考的机器。图片来源:raymazza.com
为了探索人工智能的世界,我们有必要改变自己对于人工智能是什么的想法。我们已经建造的标志性智能系统,既不下象棋,也不谋求推翻人类的统治。克里斯蒂亚尼尼说,“它们跟HAL 9000不一样。”它们已经不再仅仅在线上陪我们打发时间,或者怂恿我们去买更多的东西,而是能够在我们自己意识到之前预测出我们的行为。我们避不开它们。因此,相处的诀窍在于,承认我们没有办法知道这些选择因何作出,而是要正确看待人工智能给出的这些选择:它们是建议,是数学上的可能性。这些选择的背后,不存在什么神谕。
当人们梦想着以自己为蓝本建造人工智能时,他们向往的或许是,有朝一日能够以平等的身份,与这些会思考的机器相遇。然而,我们最终得到的人工智能却是异类,是一种我们之前不曾遭遇过的智能形式。
编译自:《新科学家》,Not like us: Artificial minds we can't understand
相关的果壳网小组
扩展阅读
人工智能之争
我们需要理解自己创造的人工智能吗?在来自截然不同领域的两位智力大鳄之间,这个问题挑起了一场看似不大可能发生的争端。
在美国麻省理工学院150周年校庆聚会上,有人请现代语言学之父诺姆·乔姆斯基(Noam Chomsky)对实现人工智能的统计方法的成功作一番点评。结果,乔姆斯基对这种方法颇不以为然。
乔姆斯基在语言学领域的工作影响了很多研究人类智能的人。他的理论的核心思想是,我们的大脑内置了与生俱来的规则。这或许可以解释一部分原因:为什么他不赞成现代人工智能实现方法,因为这种方法抛却了规则,代之以统计学关联。本质上来讲,这意味着我们不知道这些人工智能为什么会有智能,只知道它们确实有智能。
在乔姆斯基看来,统计技术的支持者就如同这样一种科学家:他们研究蜜蜂的舞蹈,精确地模拟出了蜜蜂的运动,却不追问蜜蜂为什么这样运动。乔姆斯基的观点是,统计技术做出了预测,却没有提供理解。他说:“这是一种非常新颖的成功概念。在科学史上,我没听说过类似的先例。”
谷歌公司研究总监彼得·诺米格(Peter Norvig)在他的网站上以一篇论文回击了乔姆斯基。对于乔姆斯基的统计方法只获得了“有限成功”的评论,他表示愤慨。恰恰相反,诺米格写道,这一方法如今成了占据主导地位的范式,每年产生几万亿美元的收入。作为一种学术上的羞辱,他把乔姆斯基的观点比作神秘主义,比作福克斯新闻主持人比尔·欧莱利(Bill O’Reilly)式的论断——后者曾经荒谬地批评,科学无法解释地球上潮汐的存在。
不过诺米格的主要反对意见更加基本。简单地说,他认为,像乔姆斯基这种寻求建立不断简化而且更加优雅的模型来解释世界的科学家,已经跟不上时代了。他说:“自然的黑盒子未必能用简单模型来描述。”诺米格的观点是,乔姆斯基的方法提供了一种理解的错觉,但这种方法并非植根于现实。
于是,在这场最初围绕人工智能的争辩中,知识本身的性质似乎倒成了更重要的议题。