
(文/William J. Sutherland,David Spiegelhalter,Mark Burgman)从蜜蜂数目减少的问题到核能的利用问题。科学界观点与政府政策不一致的情况屡有发生。要将科学观念贯彻到政策制定中,前路依然崎岖。
为了改善这一现状,我们开始鼓励越来越多的科学家参与政治。尽管此项举措值得赞赏,但期望科学家大举参政并不现实。另一提议是扩大首席科学顾问的作用,增加他们的数量、可用性与在政治过程中的参与度。然而,这两种方法都没有解决核心问题——议会投票者中那些科盲们。
或许我们可以向政治人物们教授科学?这个想法很吸引人,但是哪个政治人物会有如此充足的时间呢?实际上,他们几乎从不阅读科学论文和相关书籍。顾问或外部咨询人会给政治人物们阐述与时下热点相关的研究,例如线粒体置换、牛结核病、核废料处置问题等。然而,很少会有人会为了一个政策问题去精心设计一个有大量样本和明确结论的双盲随机重复对照实验。
鉴于此,针对公务员、政治人物、政策顾问、记者以及其他与科学或科学家打交道的非专业人士,我们提出了20个在培养自身科学素养时需要掌握的概念。我们认为,如果社会对这20个概念有了更广泛理解,将标志着社会的一大进步。
以下是20条建议中的后10条:
11.寻求“重复”而非“伪重复”
在大量实验、独立群体中重复出现的数据更有可能是可靠的。基于多个实验的系统回顾或元分析能够提供单一研究无法媲美的信息。简单地在一群人中挑一些个体出来并施加干预,比如在一个班级的孩子中做实验,可能会产生误导——因为这些孩子除了这个干预以外还有许多其他共同特征。如果把在这些孩子中得到的实验结果推广到其他不具有相同特点的群体中,其实就是犯了“伪重复”的错误。伪重复会导致研究者对结果产生没有根据的信心。加拿大纽芬兰大浅滩就是因为“伪重复”实验得出鳕鱼数量丰富的结论,促进了世界最大鳕鱼渔场的倒闭。
 重复有利于提高实验结果的可靠程度。但在实验设计时,需要注意避免落入“伪重复”的陷阱。图片来源:PAUL BLOW
重复有利于提高实验结果的可靠程度。但在实验设计时,需要注意避免落入“伪重复”的陷阱。图片来源:PAUL BLOW
12.科学家也是人
科学家也想在促进他们工作的过程中得到某些利益,通常是地位或研究经费,某些时候可能是更直接的经济获益。这种情况可能导致数据的刻意选择与夸大。同行评价不是绝对可靠的;期刊编辑可能更支持积极的、富有新闻价值的结果。多元、独立的数据来源及重复结果才更可信。
 “科学家也是人,他们和其他人群一样存在偏倚。但他们的确也有很大的优势:因为科学是个自我纠正的过程。”——著名生理化学家西里尔·庞南佩鲁马。图片来源:izquotes.com
“科学家也是人,他们和其他人群一样存在偏倚。但他们的确也有很大的优势:因为科学是个自我纠正的过程。”——著名生理化学家西里尔·庞南佩鲁马。图片来源:izquotes.com
13.显著性很重要
统计显著性表示一个事件出于偶然而发生的几率,用P表示。比如一项实验中实验组与对照组的差异显著性是P=0.01,这表示有百分之一的可能性是:实验处理其实没有效果,是偶然因素导致了实验组和对照组的差异。科学家习惯将P<0.05的情况称为显著。
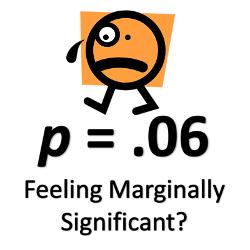 差异显著性指标常用于假设检验。通常情况下,P <0.05时,科学家才可以得出数据间具备显著性差异的结论。图片来源:cafepress.com
差异显著性指标常用于假设检验。通常情况下,P <0.05时,科学家才可以得出数据间具备显著性差异的结论。图片来源:cafepress.com
14.不显著不代表没效果
统计学上不显著(P>0.05)不代表真正的无效,只代表它的影响没有被我们检测到而已。小型研究可能不足以找出真正的差异。比如用基因改造的抗虫棉和抗虫马铃薯做的某一组实验显示,这些作物对诸如传粉者的益虫不存在不利影响,但实际上这些实验的样本量都不够大,如果有影响可能也检测不到。
 差异不显著也并不等于差异不存在。图片来源:memegenerator.net
差异不显著也并不等于差异不存在。图片来源:memegenerator.net
15.“效应量”很重要
显著性可以衡量差异是“真的”还是“假的”,但如果差异是真的,它有多大?这是所谓的效应量。一项多次重复的实验也许会得到统计上显著、但效应量很小的结果(因此,可能并不重要。)效应量的意义不是一个统计学问题,而是生物、物理或者社会层面的问题。二十世纪九十年代,美国期刊《流行病学》(Epidemiology)的主编要求作者们停止使用统计学显著性,因为他们总会误读这项数据,从而得出不科学和不正确的公共卫生政策。
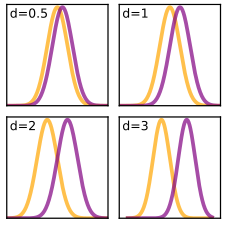 数据差异是否在统计上显著和数据均数差异的大小是不一样的概念。在差异究竟有多大时,我们需要关注效应量(effect size)。图为不同Cohen d系数所表示的差异情况。图片来源:维基百科
数据差异是否在统计上显著和数据均数差异的大小是不一样的概念。在差异究竟有多大时,我们需要关注效应量(effect size)。图为不同Cohen d系数所表示的差异情况。图片来源:维基百科
16.“关联性”会限制结论的推广
科学研究结果能否应用在实际问题上,取决于研究条件和实际情况的相似程度多大。比如从实验室动物实验中得到的结果运用到人类的时候就很有局限性。
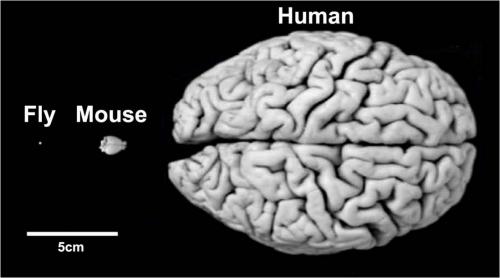 研究对象不同,研究的条件和结果会有所差异。因此不要轻易将某项研究的结论一般化。图片来源:medicalxpress.com
研究对象不同,研究的条件和结果会有所差异。因此不要轻易将某项研究的结论一般化。图片来源:medicalxpress.com
17.感觉会影响风险感知
宽泛地讲,人们通常认为“风险”=“某个时间段内某一事件发生的概率”ד这个事件所引发的结果”。很多因素都会对人类的风险感知造成不同程度的影响,包括事件的罕见性、人们自以为对事件的掌控程度、结果的不利影响、风险是否自发等。比如,美国人就会严重低估在家携带枪支的危险(1%),而严重高估住在核反应堆旁边的危险(1000%)。
 一些风险认知(横线以上)和实际风险(横线以下)的差异:从左至右依次为高温、恐怖袭击、癌症、坠机、车祸、电磁波。图片来源:susannahertrich.com
一些风险认知(横线以上)和实际风险(横线以下)的差异:从左至右依次为高温、恐怖袭击、癌症、坠机、车祸、电磁波。图片来源:susannahertrich.com
18.相关性会改变风险
计算独立事件的结果是有可能的,比如极潮、强降水和关键员工的缺席。但如果这些事件相互关联(比如风暴会导致高水位,而强降水会导致关键员工的缺席),它们共同发生的几率就比预期更大。信用评级机构对一大波次级房贷违约风险的低估就是2008年信贷市场崩溃的一个重要原因。
 风险评估必须考虑所关注的事件之间的相互关联程度。图片来源:sanguosha.com
风险评估必须考虑所关注的事件之间的相互关联程度。图片来源:sanguosha.com
19.数据是可以选择性呈现的
有时为了支持自己的观点,实验者会选择对预期结果有利的证据。譬如,一项研究认为怀孕时的酸奶摄入量和后代患哮喘之间显然有相关性,但要解读它,我们首先要知道研究者是本来就打算验证这一假说,还是在一大堆数据中偶然发现这一相关性的。相比之下,希格斯玻色子的某一段搜寻历史则是所谓“旁视效应”的例证:如果你使劲使劲找,总能找出来点儿什么。要学会问这个问题:有啥是他们没告诉我的?
 “……这是我们保存不显著结果的地方。”——不当的数据选择行为目前仍是切实存在的问题。图片来源:someecards.com
“……这是我们保存不显著结果的地方。”——不当的数据选择行为目前仍是切实存在的问题。图片来源:someecards.com
20.极端测量值可能会引起误导
由于个体能力差异、取样、偏见、测量误差等因素的影响,所有数据测量的整理结果都具有可变性。例如学校的教学效率就会因为老师的能力、受试学生的代表性、学校所处地域、指标测量方法等因素的影响而呈现差异。但在解释研究结果的时候,除个体差异之外的因素常常会被忽略掉。如果我们讨论的是极值的结果(毕业率翻倍了),比较极值和平均值的幅度(X校的毕业率是全国平均值的三倍),或者是数值的范围(表现最好和最差的学校之间有x倍的差距),这就会带来严重问题。排行榜就是其中的典型,很少有靠谱的结论。
 科学在普及、进步的过程中总会遭遇各种阻力。加深人们对科学的认识,社会最终将因此获益。图片来源:world.edu
科学在普及、进步的过程中总会遭遇各种阻力。加深人们对科学的认识,社会最终将因此获益。图片来源:world.edu
编译自:William J. Sutherland, David Spiegelhalter, Mark Burgman.Twenty tips for interpreting scientific claims.Nature.
文章题图:DAWID RYSKI. Nature.
还没看前十条呢?敬请关注《解读科学观点时,你应该知道的20个事实(上篇)》,那里有另外10个重要的事实。