
2016年3月9日,谷歌旗下Deepmind的围棋程序“AlphaGo”就要和职业九段李世石对决了。去年10月,这个程序战胜了中国棋手职业二段樊麾;那是围棋AI第一次在公平比赛中战胜职业棋手。这一成果登上了今年1月的《自然》期刊,也引发了极其热烈的讨论——而最常被提出的问题就是,AI是不是终于要占领全世界了?
 会唱歌,更会说冷笑话的Siri. 图片来源:Apple
会唱歌,更会说冷笑话的Siri. 图片来源:Apple
这个问题并不算杞人忧天,某种意义上AI已经占领了:从苹果的Siri,到日常浏览的搜索引擎,再到网络的文章推荐和商品推荐系统,这些全都是人工智能——哪怕它们不是科幻小说里那种,我们的日常生活也已经很难和它们分开。
但AlphaGo又和这些常见的AI不同。它们的差异在于学习方法和技术的通用性。
Siri:一个照本宣科的助手
Siri是一个“智能助手”,能听懂我们的口头命令,帮我们在网上搜索,帮我们在列表中找到联系人。但它的原理很简单:通过声音识别技术,将声音转化成语言的基本元素,比如元音、辅音、单词,然后和系统中内置的特殊命令比较。如果对比出来的是一个实际问题,那就执行相应的指令;如果对应上了一个空泛的问题,就从相对的段子库里挑个段子出来。
所以它的问题也就一目了然:要是你命令它去做系统中没有的命令,它就扑街了。Siri虽然是AI,但它是一个非常局限的AI:只能解决预先写好的问题。
 面对东北大哥的挑衅,Siri懵逼了(也可能只是怂了。图片来源:Apple
面对东北大哥的挑衅,Siri懵逼了(也可能只是怂了。图片来源:Apple
深蓝:下棋无人能敌,但只限下棋
1997年,IBM制造的国际象棋机器“深蓝”战胜了当时的国际象棋世界冠军卡斯帕罗夫。这在人工智能历史上是一个标志性事件。但是,虽然深蓝战胜了世界冠军,它有和Siri一样的缺点:太专了。
作为程序,深蓝的软件是专门为国际象棋设计的。它评估盘面的四项标准包括子力、棋子位置、王的安全性还有布局节奏——显然,这些指标完全依赖于国际象棋本身的规则,没有任何扩展性。
 卡斯帕罗夫对战“深蓝”的场景。图片来源:
卡斯帕罗夫对战“深蓝”的场景。图片来源:
即便如此,它也还是非常依赖于“蛮力”的。深蓝的硬件是当年最快的下棋机器,虽然有系统帮助筛选,它每秒依然要评估20亿个可能局面。为了应对这一需求,IBM当时为它开发了定制的硬件。
其结果就是,与其说它是一个国际象棋程序,不如说是一台国际象棋机器。深蓝只能下国际象棋,学不会围棋,连简单的五子棋也学不会。相比之下,作为人类的卡斯帕罗夫能学围棋,能学五子棋,还能学画画。深蓝的技术就像一把专门为国际象棋设计的钥匙,有很大局限。
自动驾驶汽车:迈出新方向
自动驾驶汽车的原理可以简化为以下几步:
-
首先它通过感应器了解周围环境,就像司机使用眼睛观察周围情况;
-
然后通过联网获得道路的路线情况,就像我们开车时候使用导航软件;
-
再然后计算机程序判断附近行人,汽车会如何运动;
- 最终计算自己最佳的线路,按着这条线路控制汽车的速度和方向。
 Google的自动驾驶汽车。图片来源:Google
Google的自动驾驶汽车。图片来源:Google
它特定于自动驾驶领域,但是基本思想和AlphaGo已经有些接近了。
IBM Watson:泛用的智能
2011年,IBM Watson在美国的真人答题节目Jeopardy!上击败了人类选手,它的技术理念更像AlphaGo。Watson的决策由四个步骤组成:首先是观察,从环境中收集数据,然后对数据做出假设,再然后是评估这些假设,最后是做出决定。不过也有些和AlphaGo不同的地方,首先它被设计成一个问答机器,其次训练Watson的时候需要人类专家的参与——比如关于癌症的问题,需要科学家们在海量的书籍论文中剔除过时的信息、错误的信息,把整理出的资料喂给机器。但至少,它能处理许多领域的能力,让它比它的同行们具有强得多的扩展可能:现在Watson已经被用于医疗领域了。
 IBM Watson的logo. 图片来源:IBM
IBM Watson的logo. 图片来源:IBM
那么,AlphaGo的技术思想是什么呢?
Deepmind创建AlphaGo,是试图通过增强学习技术(Reinforcement learning)构建通用的人工智能。它的理念中包含两个实体,一个是人工智能本身,一个是它所处的环境。人工智能和环境间的关系有两种,一种是通过传感器感知数据,另外一种是通过特定动作影响环境。因为环境的复杂性,它无法获得所有的信息,因此需要不断重复感知-反应的循环,以期望能在环境中有最大收益。绝大多数哺乳动物,包括人在内都符合这套规则。
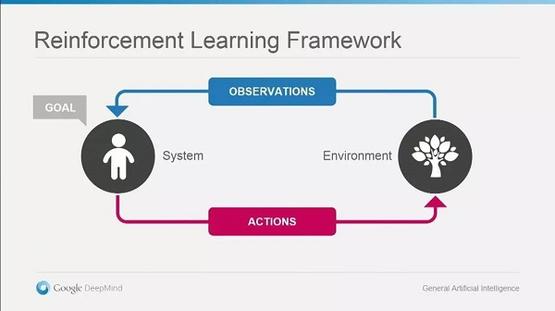 增强学习技术不断地感知和反馈环境中的信息。图片来源:Google
增强学习技术不断地感知和反馈环境中的信息。图片来源:Google
在AlphaGo之前,他们已经利用这种思想,让AI打游戏。2015年,在《自然》杂志上发表的一篇论文,描述了如何让一个算法玩不同的Atari程序,包括了《太空侵略者》和《打砖块》等游戏。AI和人一样看游戏视频,和人一样操作游戏,从游戏小白慢慢学习,变成游戏专家。AlphaGo也基于同样的原理,模拟人学习围棋的方法,它和人一样下棋,慢慢学会如何像专家一样思考。
这种技术理念所要求的是原始的数据,因此比起那些需要输入人工整理后的数据的方法有更强的通用性。原则上AlphaGo去学个围棋,五子棋都不是问题。
AlphaGo的技术首先被用于游戏的原因是因为,游戏比现实问题简单很多,无论是棋类游戏还是电脑游戏。游戏也很可能是类似技术第一个投入实用的领域:毕竟,随着游戏技术的发展,游戏开发者们逐渐意识到了好的AI和逼真的图像同样重要,不管是即时战略游戏,比如《星际争霸》还是角色扮演游戏中的NPC,高级人工智能不仅能成为强有力的对手,也可以变成优秀的团队伙伴。
但是,它最强之处当然是适应力和学习力。Deepmind声称,这种技术理念很快会被运用到医疗领域,尝试解决个性化医疗的问题。而这,肯定只是第一步。(编辑:Ent)