

(本文由 Nautilus 授权转载,译/Tzy)在今年年初的20天间,人工智能面对了一场在现实世界处理问题的重大能力测验。在宾夕法尼亚州匹兹堡的瑞弗斯赌场,一个名为Libratus的程序挑战了美国国内顶尖的四位扑克选手。他们玩的扑克游戏类型为一对一无限注德州扑克,游戏中两个玩家相互对决,通常在线比赛,在一系列的牌局中测试对方的策略,改善自己的战术,并且疯狂地唬牌。在12万手比赛后,Libratus完胜全部四个对手,赢取了1776250美元的模拟赌金,更重要的是,赢得了吹嘘自己是世界上最好的扑克玩家的资格。赛程过半的时候,和机器对战记录最好的人类玩家Dong Kim也已经差不多要认输了。“今天之前我都没有认识到它那么强。我觉得我好像在和一个作弊的人打牌,好像它能看到我的牌一样,”他对《连线》杂志说,“我不是在指控它作弊。它就是那么厉害。“
 Dong Kim是挑战Libratus的四个扑克玩家之一。 图片来源:www.pocketfives.com
Dong Kim是挑战Libratus的四个扑克玩家之一。 图片来源:www.pocketfives.com
Libratus在扑克上的胜利只是人工智能战胜它们创造者的又一个例子。当计算机掌握了诸如井字棋和西洋跳棋等相对微不足道的小游戏时,除了计算机科学家之外没有人给予太多的关注。但是在1997年,I.B.M的深蓝在国际象棋上击败了国际特级大师加里·卡斯帕罗夫。国际象棋可是许多天才毕生致力的目标,因此涌起了一波关于计算机将变得多么智能的兴趣和担忧。近期人工智能领域的进步更快了:2011年I.B.M开发的Watson打败了综艺节目Jeopardy!史上最强人类冠军,而在去年,一个名为AlphaGo的程序击败了世界上顶尖的围棋手李世乭。在这个极端复杂的游戏上,人类失去统治地位的时间点,比研究人员预测的早了10年。
 I.B.M开发的Watson打败了综艺节目Jeopardy!史上最强人类冠军。图片来源:bigthink.com
I.B.M开发的Watson打败了综艺节目Jeopardy!史上最强人类冠军。图片来源:bigthink.com
不完全信息游戏——与现实中的决策更加贴近
扑克看起来只是人工智能前进的又一步(通向反乌托邦全球统治,如果你相信科幻小说的话),但是这可能会是最意味深长的一步。和别的游戏不同的是,扑克是一个不完全信息游戏。在国际象棋和围棋中,你知道你和你对手的棋子都落在了哪里,并从这个完全确定的状态作出进一步预测;在扑克中,你不知道你的对手手中的面朝下的牌是什么,而且你必须在这个不确定的漩涡中作出决定。研究人员表示这场胜利更困难,并且或许更重要,因为现实中有如此之多决策都是建立在不完全信息上的。医生问诊病人,尽可能收集证据,做出事关生死的决策,但这些经常都是在不知道病人体内到底都发生了些什么的情况下完成的。外交官,商务谈判者和军事战略家不知道他们对手的真实状态和意图,但必须依据复杂的行动和后果的网络制定战略。
对于人工智能的研究专家而言,扑克程序不仅仅是赢得纸牌游戏的更好手段:它们是针对计算机如何基于不完全信息作出决策的实验。数十年以来,他们一直在改进他们的程序,试图追赶当今的顶尖标准——也就是我们人类。托马斯·桑德霍姆(Tuomas Sandholm)是Libratus的研发者,也是卡内基梅隆大学的计算机科学家,他已经专注于扑克12年了。他的上一个作品Claudico在2015年一场类似的比赛中败给了四个扑克专业玩家。来自阿尔伯塔大学的一个团队最近宣称他们研发的DeepStack是第一个在一对一无限制德州扑克上击败专业玩家的程序,虽然该赌场比赛的参与者表示那场比赛并没有那么激烈。既然计算机展示了它们的扑克牌比人类玩得更好,它们就有可能利用这项技能在现实生活中作出比我们更好的决策。
 来自卡内基梅隆大学的托马斯·桑德霍姆是Libratus的研发者 图片来源:post-gazette.com
来自卡内基梅隆大学的托马斯·桑德霍姆是Libratus的研发者 图片来源:post-gazette.com
强化学习让计算机生成自己独有的策略
开发一个足够聪明到可以赢得比赛的程序,需要有巧妙的方法;桑德霍姆依靠一种称为强化学习的技巧。他和他的学生教给Libratus游戏规则,并给它简单的小目标——也就是赢钱,之后让它和自己开展数万亿手的对决,试着使用击败自己的步法。程序观察了怎样的玩法会成功,怎样的玩法会失败,并利用那些结果制定战略。这种方法的一个明显优点是Libratus不会局限于别的扑克玩家的策略,它有时会创造出自己的违反直觉的步法。例如,当Libratus手持弱牌,而对手提高了赌注,程序有时也会跟着提高赌注。这可能看起来很鲁莽,毕竟这增大了惨败的几率——要是对方是因为手持好牌而提高赌注,那可就输惨了。“如果我10岁的女儿这样玩扑克,我会告诉她别这么干。”桑德霍姆对华盛顿邮报说。“但是从结果来看,这其实是一招好棋。它可以帮忙辨识唬牌。“也就是说,如果提升赌注的对方是在唬牌,他们可能被Libratus对应提升赌注的举措所吓到,认为程序可能拿着一手好牌,并因此认输。Libratus发现,对付唬牌,可以靠一手更大的唬牌。
许多近期在人工智能领域的著名进展——例如无人驾驶车,人脸识别,和自然语言处理——依赖于一种不同的方法:“机器学习”。机器学习中,计算机读取巨量的数据集并根据它们观测到的模式作出结论。对比而言,强化学习在让计算机生成自己的有创造性的策略方面可能更胜一筹。如果这是真的,那么Libratus和AlphaGo都采用强化学习来培养它们远超人类的技能就不是一个巧合了。
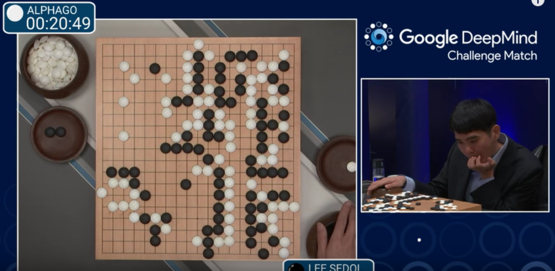 战胜李世乭的AlphaGo也采用了强化学习方法。 图片来源:tastehit.com
战胜李世乭的AlphaGo也采用了强化学习方法。 图片来源:tastehit.com
Libratus给了我们十分诱人的想法:计算机在处理复杂和重要的问题上可能终将远远强于人类。但由于技术进步飞速,我们很难确定这样的技术在未来什么时候,或是否会被成功应用。从短期来看,这个程序甚至在它自己的领域里也算不上多大的威胁。Libratus在一对一的扑克游戏中的确优势尽显;但当它转到更多玩家的比赛时,要进行的运算将更加复杂,这将超出Libratus的能力范围。即便是一对一的线上游戏,Libratus对于运算的要求也非常之高(它在超级计算机上运行,使用的处理能力和内存分别是一台高端笔记本电脑的7000倍和17000倍),把它用在研究之外的领域并不现实。目前而言,这个程序正在通过另一种方式改变扑克游戏世界——训练人类玩家。“我们真的在学习这台电脑的想法,” 被机器打败的扑克玩家之一Jason Les说。“我认为我会通过这件事成为一个更优秀的扑克玩家。”(编辑:Ent)