
|· 本文来自“我是科学家”·|
要是评选人类身上最精巧的器官,那么眼睛一定会在候选名单之中。视觉能够给我们的生活带来非常美好的体验:坐在海边一座安静的小屋门口,悠闲地看潮涨潮落,靠的是视觉;在科研机构的实验室中,科学家们通过显微镜观察细胞的各种结构,靠的是视觉;在一次商业谈判中,我们通过观察对方代表的面部表情来判断对方的心理从而让我方获取更大的利润,靠的依旧是视觉。
 目前最好的照相机也比不上人类的眼睛。图片来源:rolax
目前最好的照相机也比不上人类的眼睛。图片来源:rolax
机器有视觉吗?
视觉对于我们人类来说是一种非常重要的感觉,那么计算机是否也能具有视觉呢?答案是肯定的。计算机视觉简称CV(computer vision),在20世纪的下半叶就已经被提出。计算机的视觉器官主要是摄像头,如同我们的眼睛一样可以接受图像信号。但是如何处理与分析这些信号并产生出“认知与决策”,才是这项技术的奥秘所在。
图像在计算机的世界里通常被表示为一系列网格状的像素矩阵,这一表示形式是大多数图像处理技术的基础。我们可以通过坐标位置来确定某个像素点的位置,并通过更改该点的像素的值来更改图像的显示。图像的色彩空间常用RGB表示,即 Red,Green,Blue,空间中的 RGB 分布取值范围都在 [0, 255],呈均匀分布。同人类理解世界一样,对于计算机来说同样有“知识的表示形式决定了学习的难易程度”。
 分别输入R、G、B值就能得到想要的颜色了(上图中A指透明度,取值在0-1)。图片来源:Pixabay
分别输入R、G、B值就能得到想要的颜色了(上图中A指透明度,取值在0-1)。图片来源:Pixabay
为了更好的表示图像信息,还有两种常用的颜色空间表示方法, 一是HSV: 色调 Hue,饱和度 Saturation,亮度 Value。这个空间中的颜色分布呈现为一个圆柱体。由于色调通道在不同的光照条件下变化范围不大,而亮度通道则在不同的光照条件下变化明显,因此可以通过调整色调通道的值来更好的选择目标区域而避免光照条件的影响。
二是HLS:色调Hue, 亮度Lightness, 饱和度Saturation,这个标准几乎包括了人类视力所能感知的所有颜色,是目前运用最广的颜色系统之一。由于在大部分计算机视觉应用中,光照条件对于算法的识别能力是有影响的,后两种颜色空间表示方法考虑了亮度信息,因此可以用于图像的光照条件的分辨。
图像处理主要是通过图像增强、图像恢复使得图像更加清晰,从而方便人们进一步观察和分析。例如20世纪50年代末,卫星航拍的图像往往不够清晰,这时候人们通过计算机的图像增强功能来获取更加清晰的图像,从而帮助为专家分析提供便利。而模式识别主要是指识别出图像中某些特定的“概念”,例如找出图片中的一只猫,或在一张充满汉字的图片上找到某个特定的汉字。如何能在一个基于数学和逻辑的机器上形成某种“概念”,成为了模式识别和机器学习研究的重点与突破性的技术。
 不知道这张“猫片”机器能不能识别出来?图片来源:Unsplash
不知道这张“猫片”机器能不能识别出来?图片来源:Unsplash
模式识别在20世纪60年代初开始就被广泛的认可,例如当时就已经具有了能够识别图片中的英文字符的识别程序,虽然识别效果和现代的技术不可同日而语,但还是能够减少一部分人工的工作量(人们不再需要将字符一个个手动输入计算机)。尽管当时计算机视觉在二维的图像增强和模式识别这两个领域已有广泛应用,但人们并不满足于此。我们人类看到的世界是一个三维的世界,因此人们也希望计算机也能够看见一个三维的世界? 1965年罗伯特的研究是计算机视觉研究从二维转向三维的标志。通过一遍遍地让计算机观察圆锥、圆球、立方体等模型的照片,以及一遍遍地调试程序,罗伯特成功地让计算机识别出了二维图像中的三维结构和空间布局。这使得从二维图像中提取三维信息成为了可能。从此,计算机视觉得到了突飞猛进的发展。
 罗伯特成功地让计算机识别出了二维图像中的三维结构和空间布局。图片来源:sogoucdn
罗伯特成功地让计算机识别出了二维图像中的三维结构和空间布局。图片来源:sogoucdn
计算机视觉能帮我们做什么?
到了今天,计算机视觉在众多领域都得到了广泛的应用。在图像增强方面:图像增强已被广泛应用于医疗、航空航天以及交通监控等方面。例如,以往X光检测中由于一些脏器的特殊结构而使得这些器官在X光片中清晰度不够,从而会给诊断带来极大不便。但将图像增强技术应用于这一领域就可以很好地解决这一问题,使得医生对病人病情诊断更加准确。在航空航天以及工业领域中,图像增强可以有效地去除图像中的干扰,获取更为清晰的图像以供分析,在图像增强和更先进的光学镜头帮助下,人们在一些军用卫星拍摄的照片中甚至能清晰地分辨出地面上几厘米长度的线段。在交通监控领域,图像增强技术也带来了巨大的便利。在晴朗的天气中,交通摄像头固然能够良好运作,而在雨天、雾天或是夜晚,摄像头取得的图像会受到干扰,此时,图像增强就可以在一定程度上去除这些干扰,更好地监控路面信息以维护我们的安全。
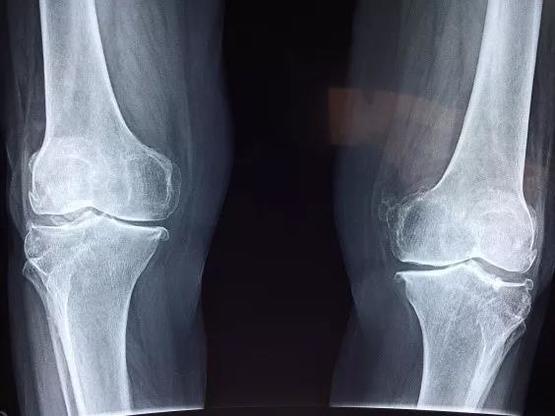 图像增强技术可解决X光片的清晰度问题。图片来源:cdn.sohucs
图像增强技术可解决X光片的清晰度问题。图片来源:cdn.sohucs
而在模式识别方面,计算机视觉的发展就更令人惊叹。现在我们拿起手机拍照时,手机不仅能够快速且准确地在图片中识别出人脸的位置,并且能够识别出人脸的表情,在微笑时自动拍照(微笑快门)。此外,相信女生们对于手机拍照中的美颜功能并不陌生,在自拍之后要用美颜把自己P得美美的。而现在的手机能够准确识别出五官的位置,在拍照时就有针对性地对眼睛、鼻子、皮肤进行相应地美颜,从而省去了人们在拍照之后还要花时间去处理的烦恼。2015年,微软推出了一个网站How-old.net,在这个网站一经推出就刷爆了朋友圈和微博,这个网站可以对人们上传的图片中的人脸进行识别,并根据相应算法预测出其年龄,虽然有时候结果不够准确,但完全不影响人们乐此不疲地上传照片。在我们去乘坐地铁,火车或飞机时,我们的行李从安检仪中快速滑过时,此时计算机就能根据X光图像将行李箱中的物品进行识别,并通过不同的颜色清晰地呈现在安检员的面前。
如何让计算机理解“眼前”的世界?
在计算机视觉发展之初,其研究还仅限于“看见”。对于我们人类来说,视觉不仅仅是为了看见,而是为了对看见的事物做出反应,或是更好地理解这个世界。因此,专家们也希望能够赋予计算机这样的能力。一款名为“Kinect”的摄像传感器能够捕捉到站在摄像头前的人以及这个人做出的动作。根据不同的动作,“Kinect”背后的计算机会做出不同的反应。这也就是人们常说的“体感游戏”。这种不需要手柄而是靠自己身体动作来操纵的游戏机在当时受到了热烈的追捧。
另外还有一项计算机视觉技术也正逐步来到我们身边:我们在看电影时一定都见过这样的场景,在一个人流量巨大场所(比如机场),警察们为了追踪一个坏人,在监控室中将坏人的头像与监控器中的人脸进行比对,在经过短暂的比对后,坏人的人脸在监控画面上被标了出来,这种人脸识别技术已经十分令人惊叹,而更令人惊叹的是,监控摄像头锁定了目标,一直自动跟随着目标移动,直至坏人被警察抓住。这样的跟踪摄像头其实已经出现在我们的生活中,相信很快它将开始为大家服务。
 现在的摄像头越来越先进啦。图片来源:Unsplash
现在的摄像头越来越先进啦。图片来源:Unsplash
尽管这两个例子中的计算机视觉,已经不局限于“看见”这一基础的层面,但这两个例子中计算机对于图像的反应都比较简单,它们并不需要理解他们看到的是什么,只需要根据设计好的程序,在出现特定图像时做出特定的动作即可,对于人类来说,这几乎是与生俱来的本领。人类随着年龄的增长,能够识别出图像中的不同物体,并且通过不断的观察学习,在三五岁时就能够认出一只躲在箱子后面只露出半张脸的小猫。
计算机能不能也在图片中识别出图片中的物体呢?有人可能会问,上面不是说了计算机能够识别出人脸吗?kinect不是也能够识别出人的动作吗?但是这都是识别一种物体(也就是人),而且仅仅是识别出人脸这一项,就要耗费科学家大量的精力去建立模型、设计算法。按照这一思路,想让计算机识别出生活中的所有物品就需要给每个物品设计大量的模型,这几乎是一项不可能完成的任务。
 用这种思路识别生活中的每一件物品是不可能完成的任务。图片来源:Pixabay
用这种思路识别生活中的每一件物品是不可能完成的任务。图片来源:Pixabay
1981年诺贝尔医学生理学奖颁发给了神经生物学家大卫·休伯尔(David Hubel)和托斯坦·维厄瑟尔(Torsten N. Wiesel)。他们发现了视觉系统信息处理机制,证明大脑的可视皮层是分级的,大脑的工作过程是一个不断迭代、不断抽象的过程。 视网膜在得到原始信息后,首先经由区域V1初步处理得到边缘和方向特征信息,其次经由区域V2的进一步抽象得到轮廓和形状特征信息,如此迭代地经由更多更高层的抽象最后得到更为精细的分类。像素是没有抽象意义的,但人脑可以把这些像素连接成边缘,边缘相对像素来说就变成了比较抽象的概念;边缘进而形成球形,球形然后到气球,又是一个抽象的过程,大脑最终就知道看到的是一个气球。
这个生理学的发现,促进了计算机视觉的发展。计算机专家仿照人类大脑由低层到高层逐层迭代、抽象的视觉信息处理机理,建立深度网络模型。深度网络每层代表可视皮层的区域,深度网络每层上的节点代表可视皮层区域上的神经元,信息由左向右传播,其低层的输出为高层的输入,逐层迭代进行传播。
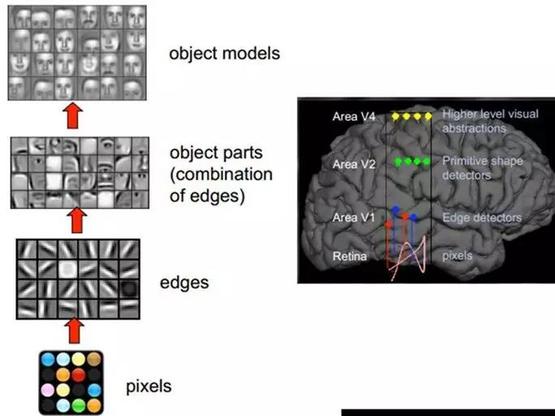 逐层迭代的深度网络模型。图片来源:eefocus
逐层迭代的深度网络模型。图片来源:eefocus
比如看到一张图片中的摩托车,在大脑中可能就几微秒的时间,但是经过了大量的神经元抽象迭代。对计算机来说,最开始看到的根本也不是摩托车,而是RGB图像三个通道上不同的数字。所谓的特征或者视觉特征,就是把这些数值给综合起来用统计或非统计的形式,把摩托车的部件或者整辆摩托车表现出来。大部分的设计图像特征都是把一个区域内的像素级别的信息综合表现出来,利于后面的分类学习。若输入层为输入数据的特征表示,则高层的特征则是低层特征的组合,从低层到高层的特征表示越来越抽象的人类视觉系统信息处理过程。
在2007年,科学家开始将人工神经网络与计算机视觉相结合,让计算机能够自主学习和理解所看到的内容。他们让计算机观看了上亿张图片,并且告诉计算机每张图片中每个物品的名称(这是一项巨大的工程,167个国家和地区的约5万名工作者耗费了近2年时间才完成这一工作)。计算机观看并学习了如此大量的图片之后,能够准确地分析出一张新的照片上的大部分物体,并且能够简单地描述一张图片。对于计算机视觉研究来说,这无疑是十分重大的突破。
 计算机观看并学习了如此大量的图片之后,能够准确地分析出一张新的照片上的大部分物体,并且能够简单地描述一张图片。供图:sussex
计算机观看并学习了如此大量的图片之后,能够准确地分析出一张新的照片上的大部分物体,并且能够简单地描述一张图片。供图:sussex
计算机视觉中最常使用卷积神经网络(CNN),进行图像识别研究。卷积是在连续空间做积分计算,然后在离散空间内求和的过程。实际上在计算机视觉里面,可以把卷积当做一个抽象的过程,就是把小区域内的信息统计抽象出来。比如,对于一张爱因斯坦的照片,可以学习多个不同的卷积和函数,然后对这个区域进行统计。
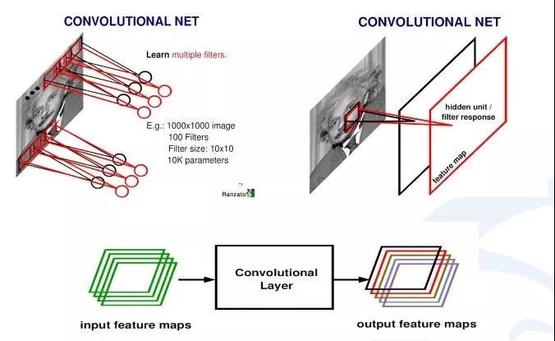 卷积层。图片来源:eefocus
卷积层。图片来源:eefocus
卷积神经网络学习好的卷积和会对输入图像进行扫描,每一个卷积和会生成一个扫描的响应图(即feature map)。 从一个最开始的输入图像(RGB三个通道)可以得到256个通道的响应图,即 256个卷积和,每个卷积和代表一种统计抽象的方式。
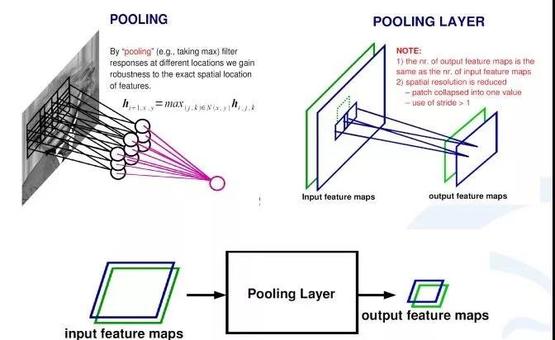 池化层。图片来源:eefocus
池化层。图片来源:eefocus
在卷积神经网络中,除了卷积层,还有一种叫池化的操作。池化操作就是一个对一个小区域内求平均值或者求最大值的统计操作。在内积结果上取每一局部块的最大值就是最大池化层的操作,由卷积层得出的每一个响应图经过一个求最大的一个池化层,会得到比原来响应图更小的响应图。卷积神经网络通过卷积层和池化层实现了图片的特征提取。
今天的计算机视觉技术包括了诸多不同的研究方向,关注度高的一些领域有目标检测、语义分割、运动和跟踪、视觉问答等。其中目标检测一直是计算机视觉中非常基础且重要的一个研究方向——通过给定的输入图片识别图片中的特定物体,并输出其所属类别及位置,根据检测对象不同,也衍生出人脸检测、车辆检测等细分的检测算法。目标检测和识别通常是将是将“宏观”上的物体在原图像上框出,语义分割则是将每一个像素上进行分类,图像中的每一个像素都有属于自己的类别。近年来用在无人车驾驶技术中分割街景来避让行人和车辆、医疗影像分析中辅助诊断等。 跟踪问题研究的是在一段给定的视频中,根据第一帧所给出被跟踪物体的位置及尺度大小,在后续的视频中去寻找到被跟踪物体的位置,并在跟踪过程中需要适应各类光照变换,运动模糊以及表观的变化以提高检测的精度。视觉问答是近年来十分热门的研究方向之一,其研究目的旨在根据输入图像,由用户进行提问,而算法自动根据提问内容进行回答。此问题跨越两种数据形态,故也称之为跨模态问题。
 如今,计算机视觉的研究成果正不断给我们的生活带来便利。图片来源:Pixabay
如今,计算机视觉的研究成果正不断给我们的生活带来便利。图片来源:Pixabay
如今,计算机视觉的研究成果正不断给我们的生活带来便利。最后,我们来构想一个小场景:在一个天气晴朗的假日,你开着车飞驰在田间小路上,车上的摄像头和计算机正一刻不停地帮我们分析路况,判断路上的每一种障碍物究竟是团无害的干草,还是会对行车造成威胁的石块。当你驶过一个路口时,在你毫无察觉的前提下,路口的监控摄像头已经扫描过了你的面部,并与数据库中的坏人进行比对,并认定你不在坏人的名单上。在路边,你发现了一片十分美丽的野花,于是你下车去观赏。花实在是太美丽了,你掏出手机,扫描了一下自己的脸或是指纹将手机解锁,然后打开一个识别植物种类的APP,用手机拍下上传,几秒钟之后,你就知道了这朵花的名字。之后你重新发动汽车准备启动,车载摄像头发现车的左后方正有个小孩骑着自行车而来,车上的显示屏立即显示出摄像头观察到的危险画面,你因此避免了一场车祸……在这个想象的场景中有着多种计算机视觉研究成果的应用,一些已成为现实,而一些在不久的将来,也将走进我们的生活。(编辑:Yuki)
作者名片

